The DementiaBank Acoustics Project is a working title for an acoustic-only challenge for AD detection. This document serves as the lab notebook for this project.
This project will attempt to replicate some of the results of Wang 2019 and Martinc 2021, but focusing on minimizing human involvement; we will first work on raw transcript classification with ERNIE (cutting all CHAT annotations), then introduce pause-encoding in a manner similar to Yuan 2021 which is automated by MFA. Goal is to replicate the results of Yuan 2021/or even Martinc 2021 in a completely automated manner.
Background Reading
I first began by doing a literature survey on the ADReSS Challenge results published in the Frontiers AD special interest group issue.
Proposal
And then, we wrote a proposal: DementiaBank Acoustics Project Proposal
Brainstoming
More notes from the meeting: DementiaBank Acoustics Brainstoming
Protocol Notes
July 1st
- Began by moving a subsample of Pitt’s Cookie Theft to
pitt-7-1in therawdata folder - Ran
floon all collected samples. Arguments used are the same as that for batchalign, except we filter out theINVtier as we are detecting AD on patient and not investigator: soflo +d +ca +t* -tINV - Moved all collected samples (and changed extension to .txt) to the same sub-folder, but in
transcripts_nodisfluency
July 2nd
- Created a dataprep script
dataprep.pywhich dumps a pickled copy of cleaned data totranscripts_nodisfluency/pitt-7-1.dat. - Created sliding windows of 5 pieces of dialogue concatenated, stored it in
transcripts_nodisfluency/pitt-7-1-windowed.dat - Used tencent/HuYong’s
nghuyong/ernie-2.0-enErnie 2.0 model, the continuous language model from Baidu (Layer:12, Hidden:768, Heads:12)
July 4th
- Finalized training code. Selected base hyperparameters {bs: 8, epochs: 2, lr: 3e-3, length: 60}. Again, we are using Baidu’s
nghuyong/ernie-2.0-en. - Started training fastcalculator on
24bc812
train: faithful-frog-3
{bs: 8, epochs: 2, lr: 3e-3, length: 60, pitt-7-1-windowed.dat }
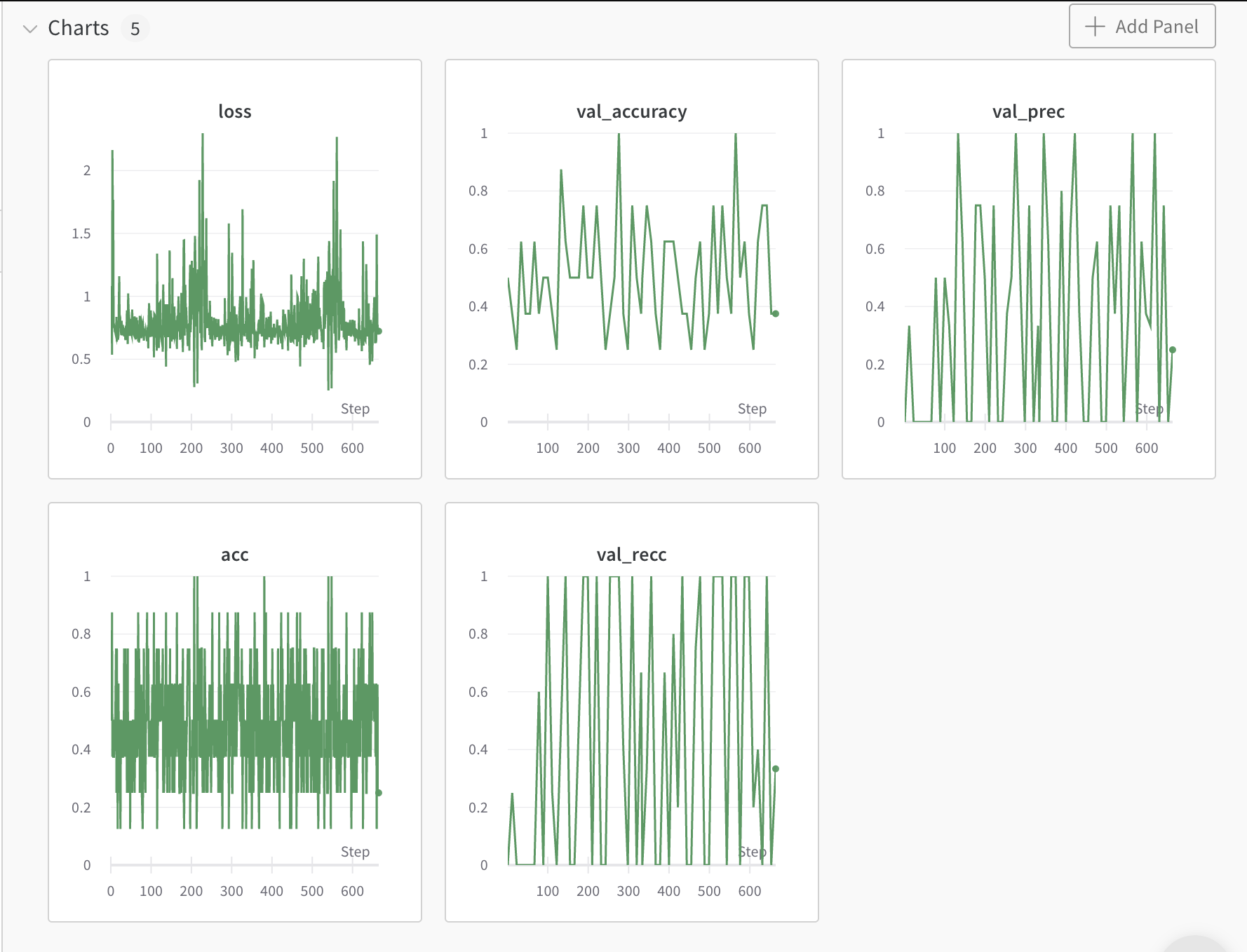
- Commentary: LR could be too high, looking at the divergent loss behavior.
- Decision: dropping bs to
4and lr to1e-5, similar to previous transformers. Also training for 3 epochs.
train: revived-disco-5
{bs: 4, epochs: 3, lr: 1e-5, length: 60, pitt-7-1-windowed.dat }
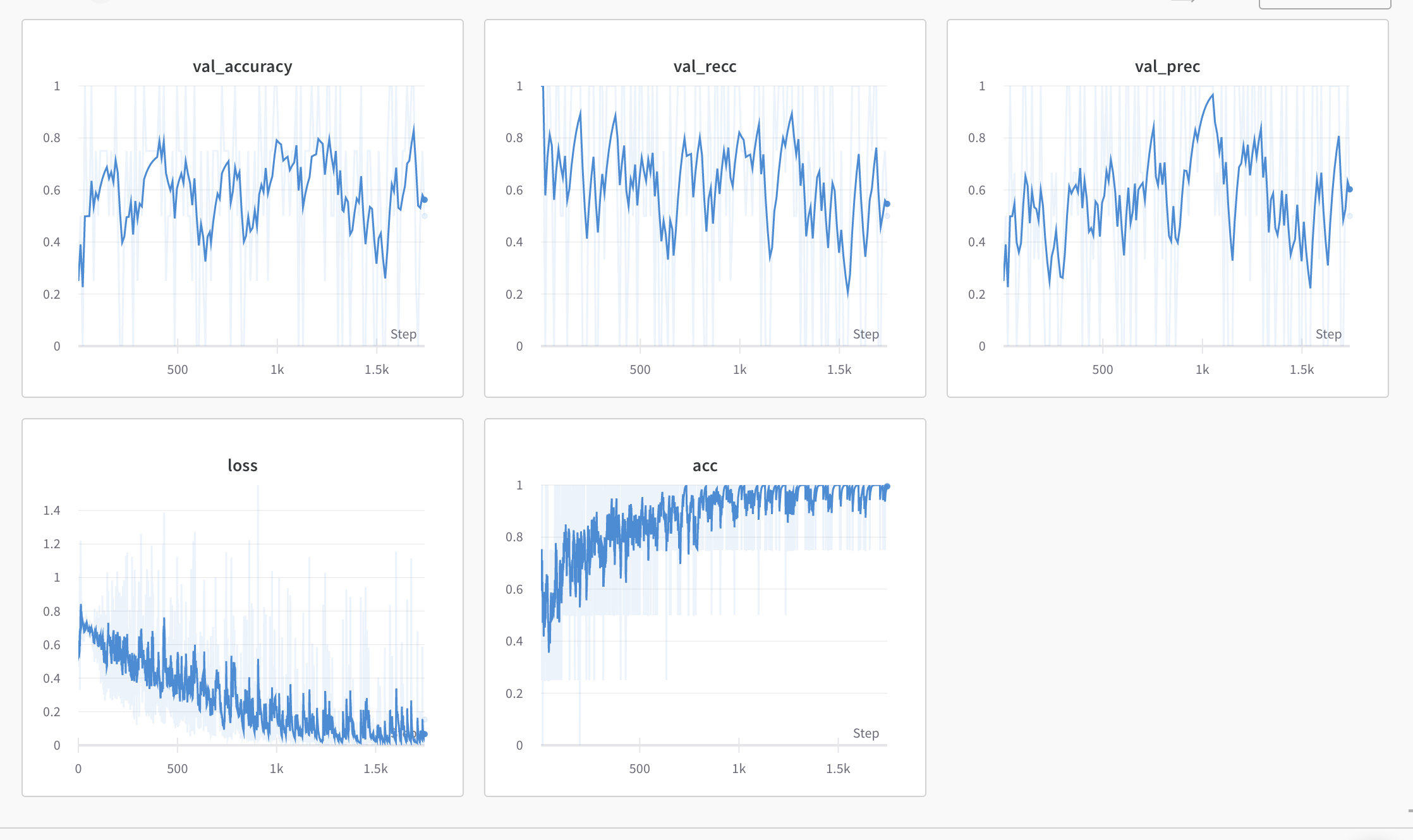
- Commentary: quintessential overfitting
- Decision:
- Made the corpus bigger
- cleaned the entire Pitt corpus (
pitt-7-4in therawfolder) to become training data. Similar topitt-7-1, ranfloon all collected samples; arguments used are the same as that for batchalign, except we filter out theINVtier as we are detecting AD on patient and not investigator: soflo +d +ca +t* -tINV; theflo’d results are intranscripts_nodisfluency. - the notable difference between the previous dataset
7-1and the current one7-4is that the7-4are prepended numbered by the task (cookie/100-01.cha> =cookie-100-01.txt) - New (full) Pitt data as prepared above is ran though the dataprep script as of
b325514cfad79da82d7a519ed29ea19ed87b2be4(difference is that empty/dummy files are ignored), and pickled attranscripts_nodisfluency/pitt-7-4.datandtranscripts_nodisfluency/pitt-7-4-windowed.datrespectively. - For new data, window size is still
5, splitting10cases out for testing now instead of5.
- cleaned the entire Pitt corpus (
- Made the corpus bigger
train: vocal-oath-6
{bs: 4, epochs: 3, lr: 1e-5, length: 60, pitt-7-4-windowed.dat}
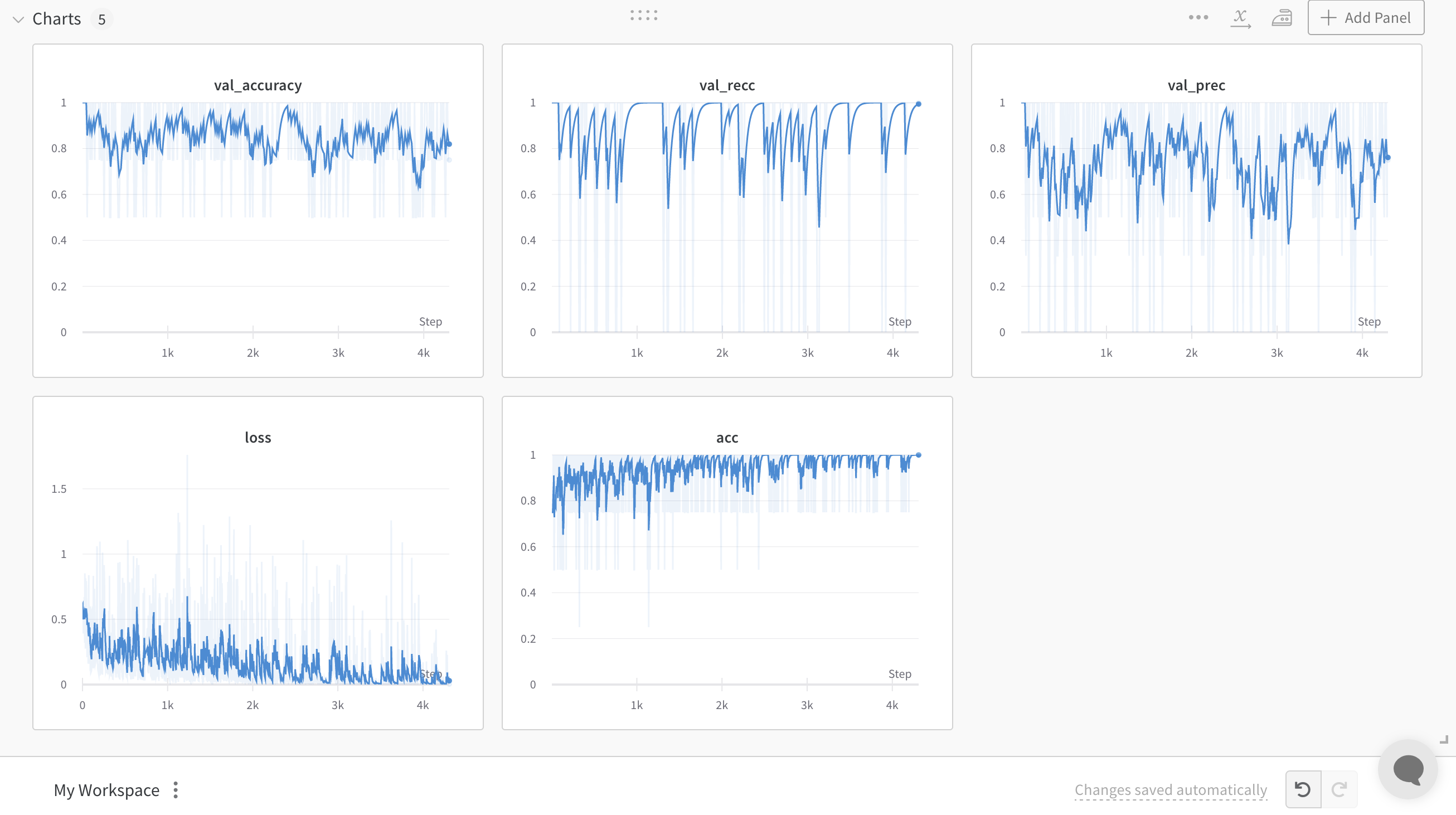
- Commentary: high recall, low precision. Perhaps classes aren’t balanced?
- Spoiler alert: they are not.
- An inspection of data reveals that there is 3211 rows of dementia, 2397 rows of control
- Decision:
- Created
pitt-7-4-balandpitt-7-4-windowed-balseries of data based on dataprep.py on703f79248a20fd7a13a5033ca2bf7f691f42c941. This version force-crops to make sure that the dementia and control indicies have the exact same length for each class.
- Created
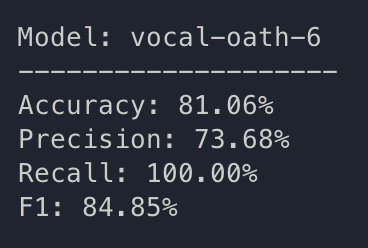
train: helpful-leaf-7
{bs: 4, epochs: 3, lr: 1e-5, length: 60, pitt-7-4-windowed-bal.dat}
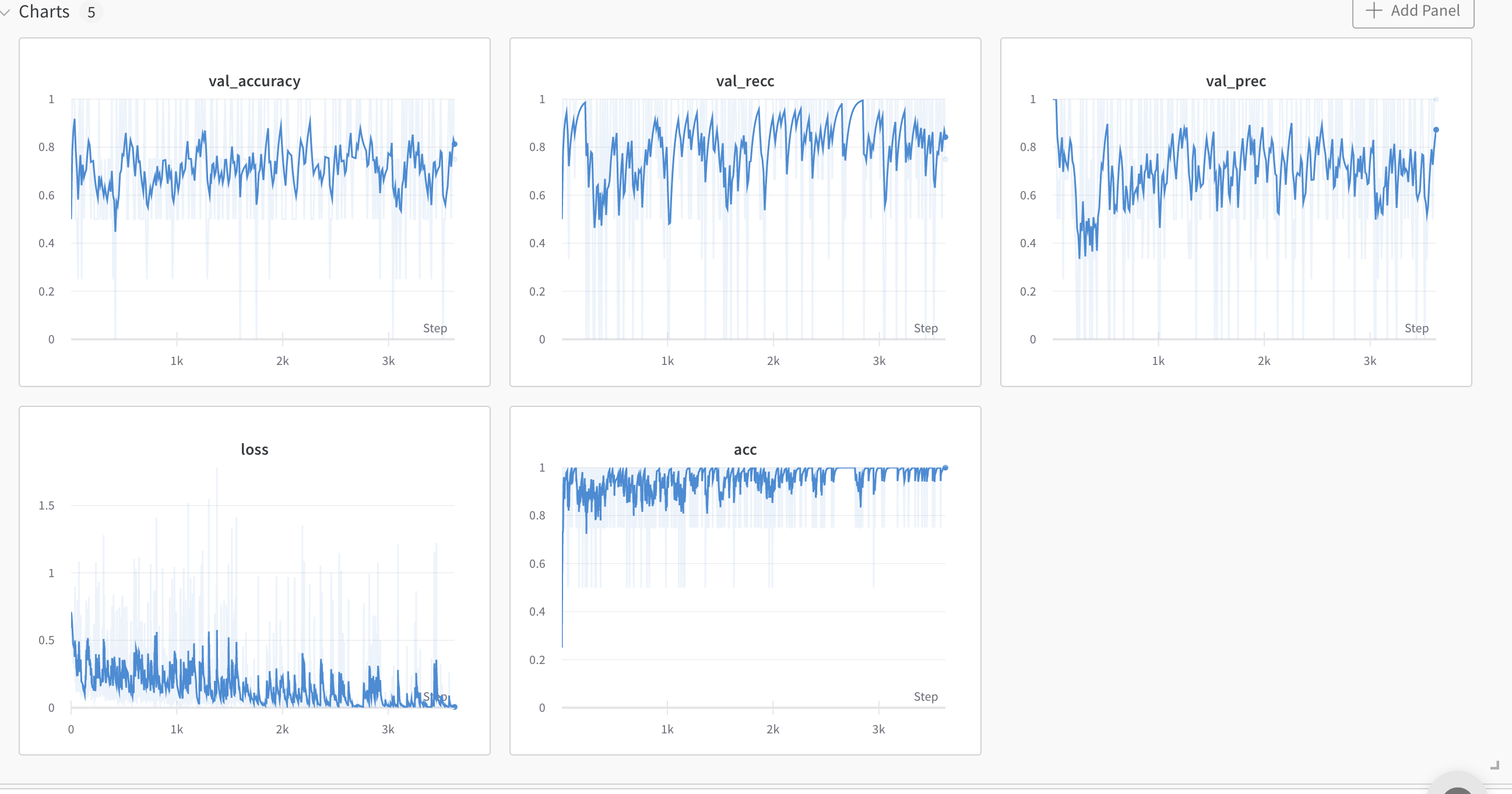
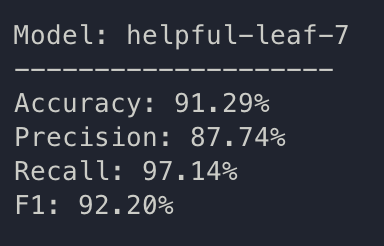
Beautiful. Question now is whether or not there is data leakage/external heuristics. It is a good time to do some LOOCV. Getting this result without any disfluency calculations seems unlikely.
But anyways, going to discuss these results as they seem to meet results we see in Yuan 2021, even without top-N ensemble; though this is one trial, LOOCV may still show that we actually need it.
July 5th
- Began the day with creating the script k-fold validation; I originally hoped to exactly replicate the procedure of Yuan 2021 for comparability, but, not sure how they got the actual result of a min/max range with LOOCV on binary; therefore, we will instead create a 95% confidence interval analysis via a single-variable t test on standard k-fold validation. K=50
- During one-off testing, another set of hyperparameters seems to work too: {bs: 72, epochs: 3, lr: 1e-5, length: 60, pitt-7-4-windowed-bal.dat}. As we have not begun tuning for hyperparameters, we are just going to use this set, K=50, for the first k-fold trial.
k-fold: F4ZVbGfdBAQvtvXemWZCZD
code: 55f77ff1dea03c3ed66967864dc52fd2c0062f23

{bs: 72, epochs: 3, lr: 1e-5, length: 60, pitt-7-4-windowed-bal.dat} K = 50
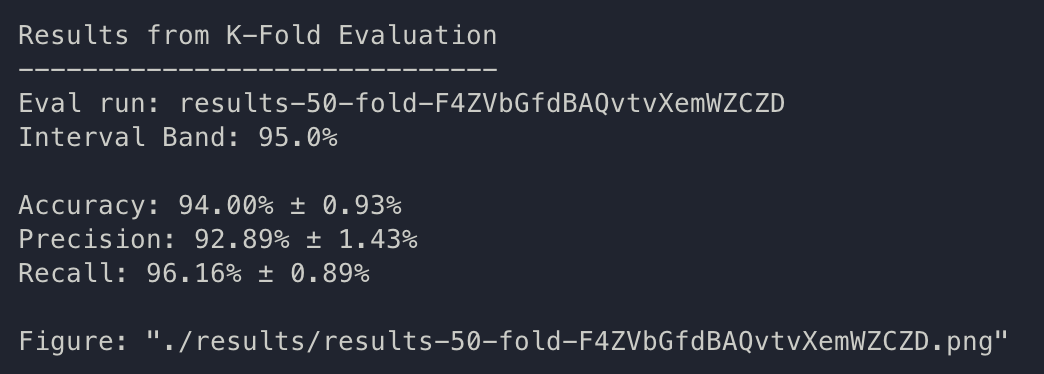
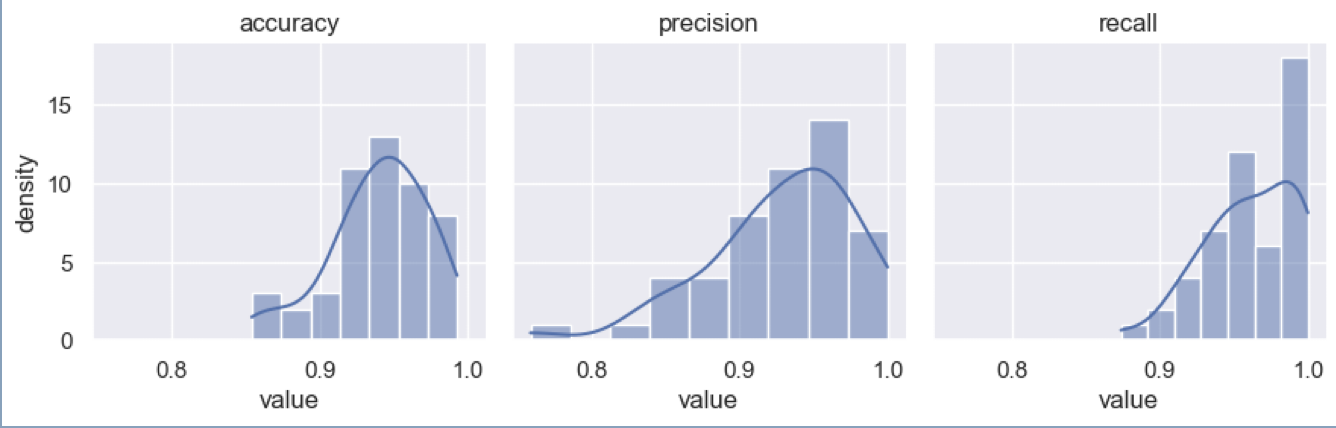
It seems like the results we got is consistent and validates in a manner which we expect.
July 7th
Yesterday was a day filled with working on batchalign, but we are back now. Today, I aim to look into the heuristic that I identified yesterday by playing with the model, which is that it seems like the model prefers the use of long-focused sentences about cookies, so the heruistic its picking up is probably on-topicness.
I am going to first leverage the lovely cdpierse/transformers-interpret tool to help build some explainability by adding it to validate.py. Upon some human validation with random sampling, the model seem to do less well than I’d hoped. Running a train cycle with the new results/params seen above to see if it does better.
train: brisk-oath-10
{bs: 72, epochs: 3, lr: 1e-5, length: 60, pitt-7-4-windowed-bal.dat}
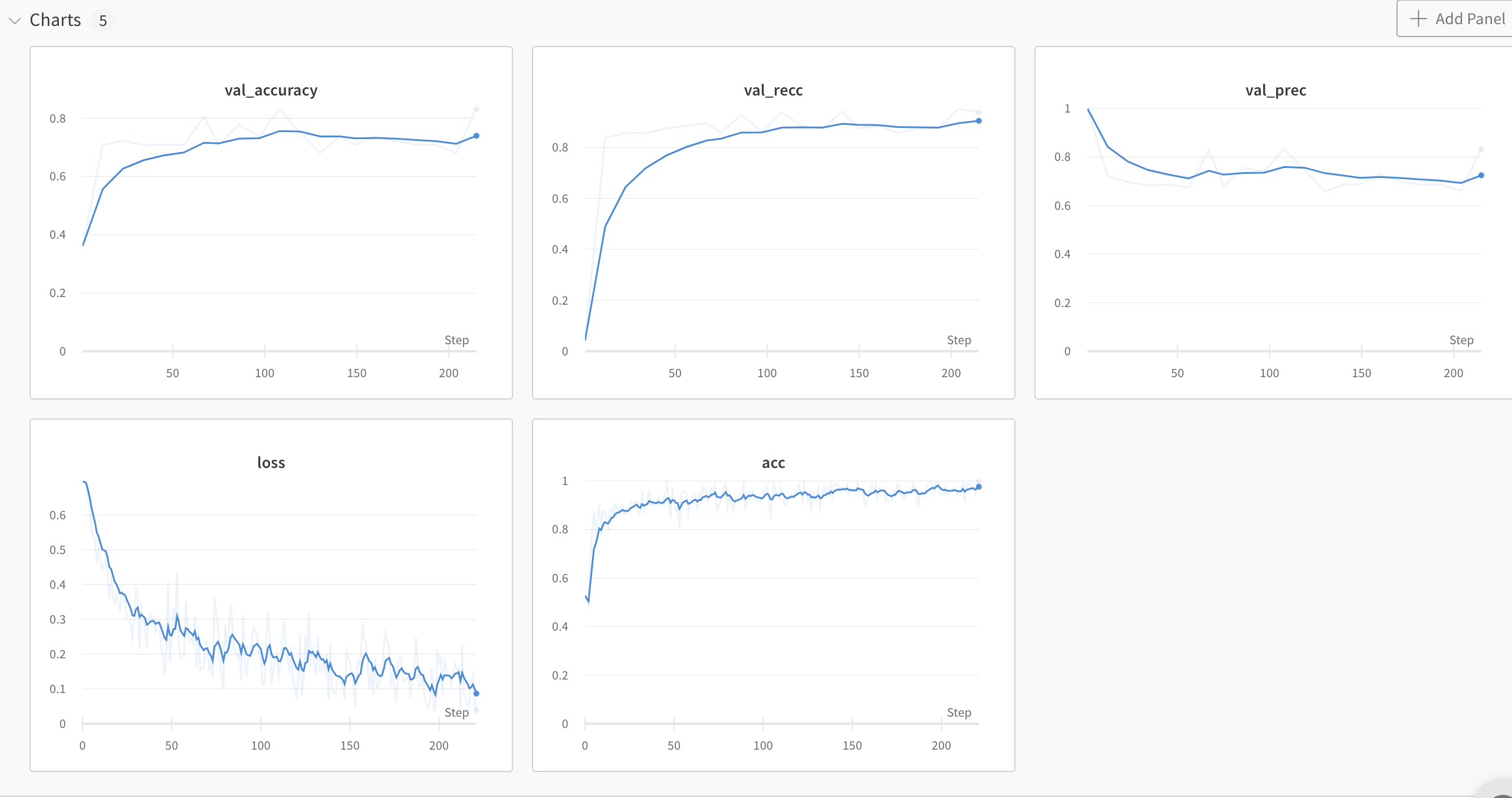
- Commentary: It seems like the model is doing overall worse from validation data, but it does fairly well during test data.
- Decision:
- I can fairly confidently claim that the model is just fitting on topic. As in, if the topic is about cookies (theft/taking/cookie/mother/etc.), it will be classified as control.
- One thing that we can do is to claim this task as directly task-controlled: that is, include no data except cookie and control for that difference
- Then, the model would’t be able to predict the result b/c the variation in topic won’t have influence.
- This is going to be prepared in the
cookiepitt-7-7-bal*based ondataprep.pyin commit518dec82bb961c0a8ad02e3080289b56102aa1a2
train: super-durian-11
{bs: 72, epochs: 3, lr: 1e-5, length: 60, cookiepitt-7-7-windowed-bal.dat}
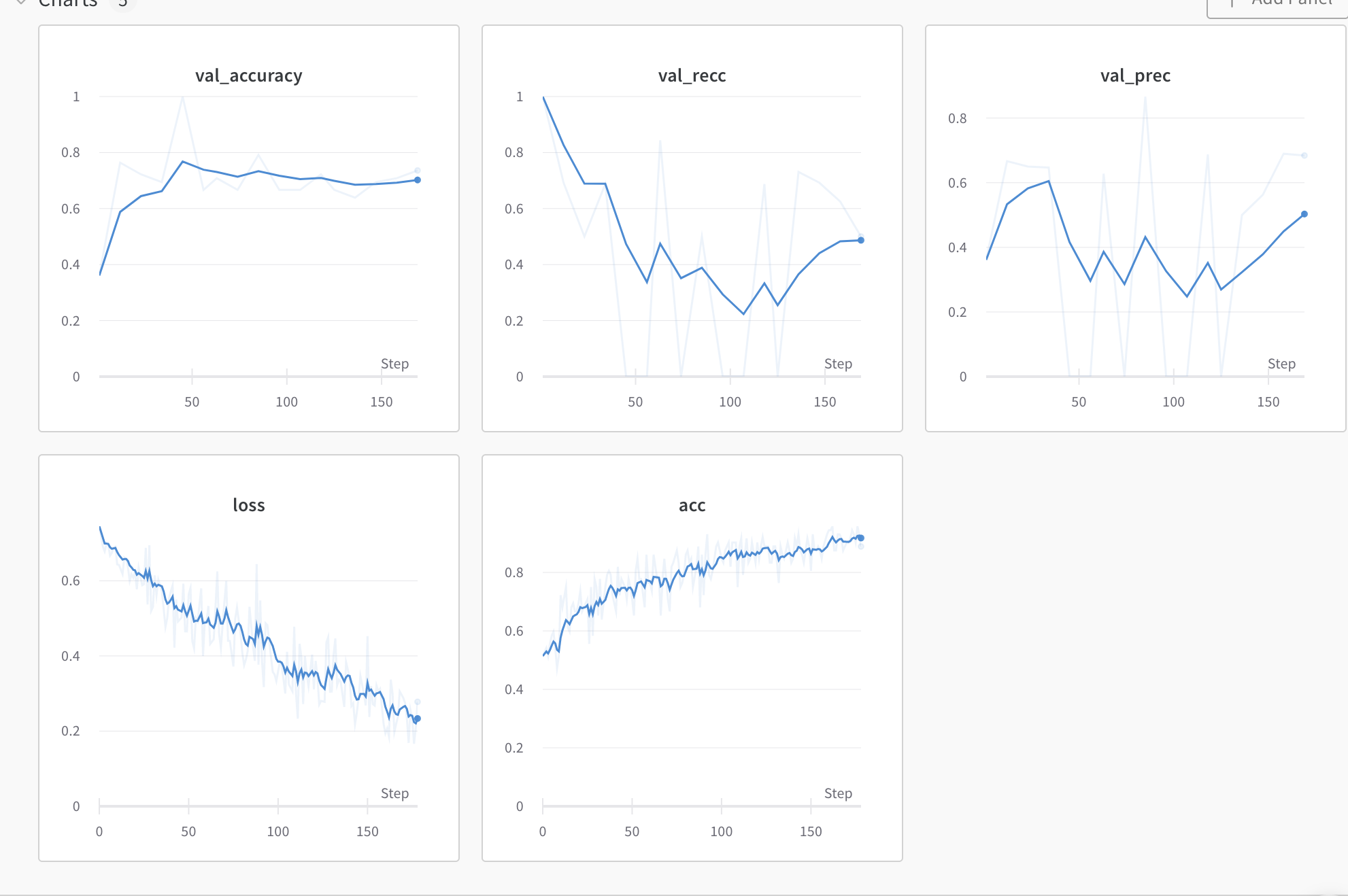
- Commentary: the model is no where near convergence
- Decision: multiplying the LR by 10
train: floral-sunset-12
{bs: 72, epochs: 3, lr: 1e-4, length: 60, cookiepitt-7-7-windowed-bal.dat}
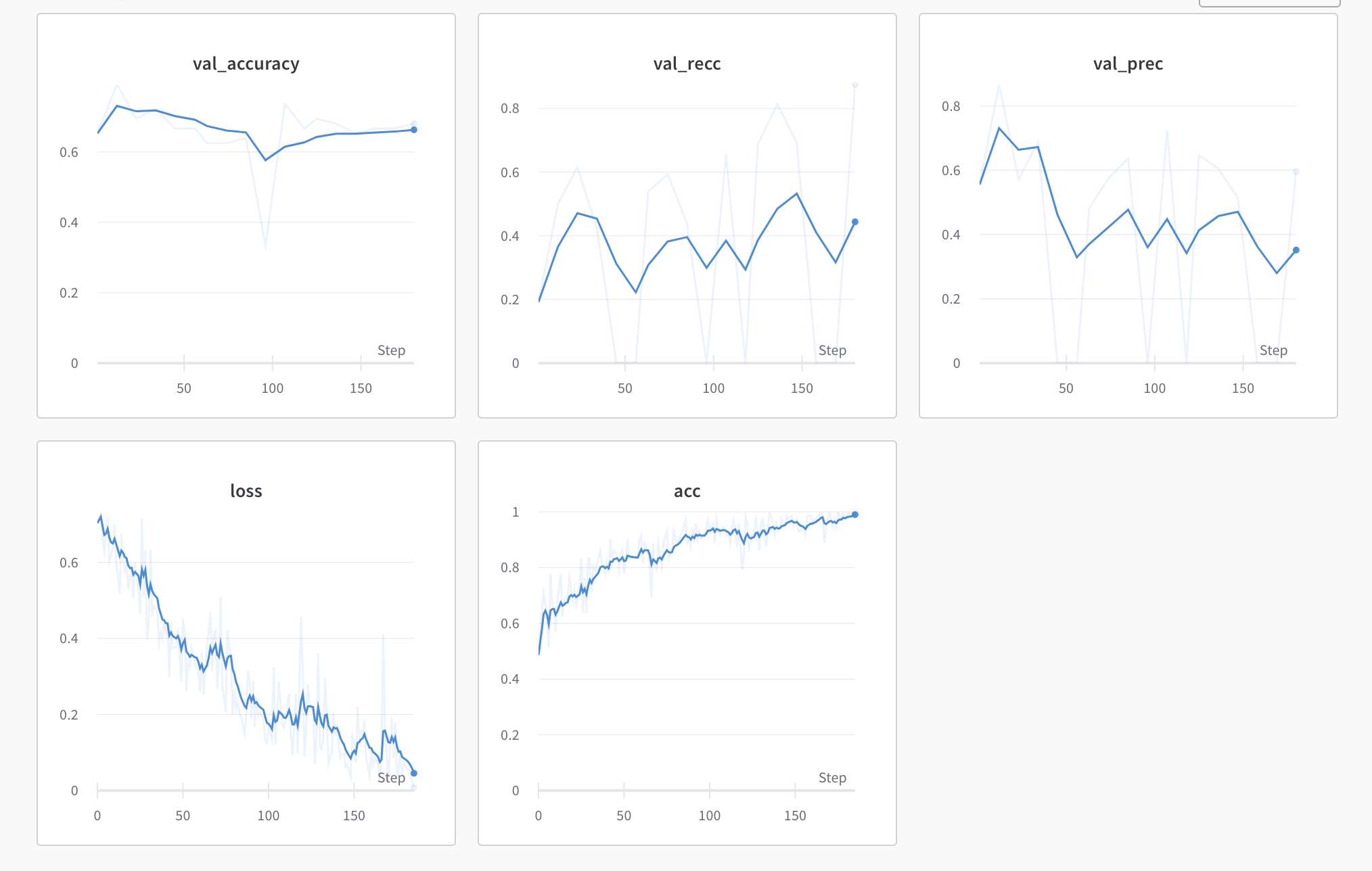
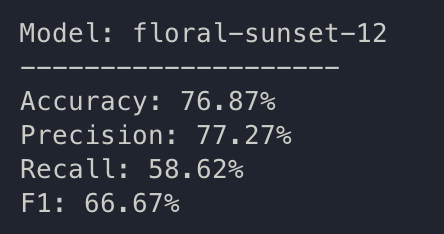
- Commentary: There we go. This seem to be more in line with what we see in Yuan 2021
- Decision: ok, let’s elongate the actual content. Perhaps we can try a 7-element search instead? This is written as
cookiepitt-7-7-*-long. Code based on9e31f4bc13c4bfe193dcc049059c3d9bda46c8d0
train: sweet-plasma-13
{bs: 72, epochs: 3, lr: 1e-4, length: 60, cookiepitt-7-7-windowed-long-bal.dat}
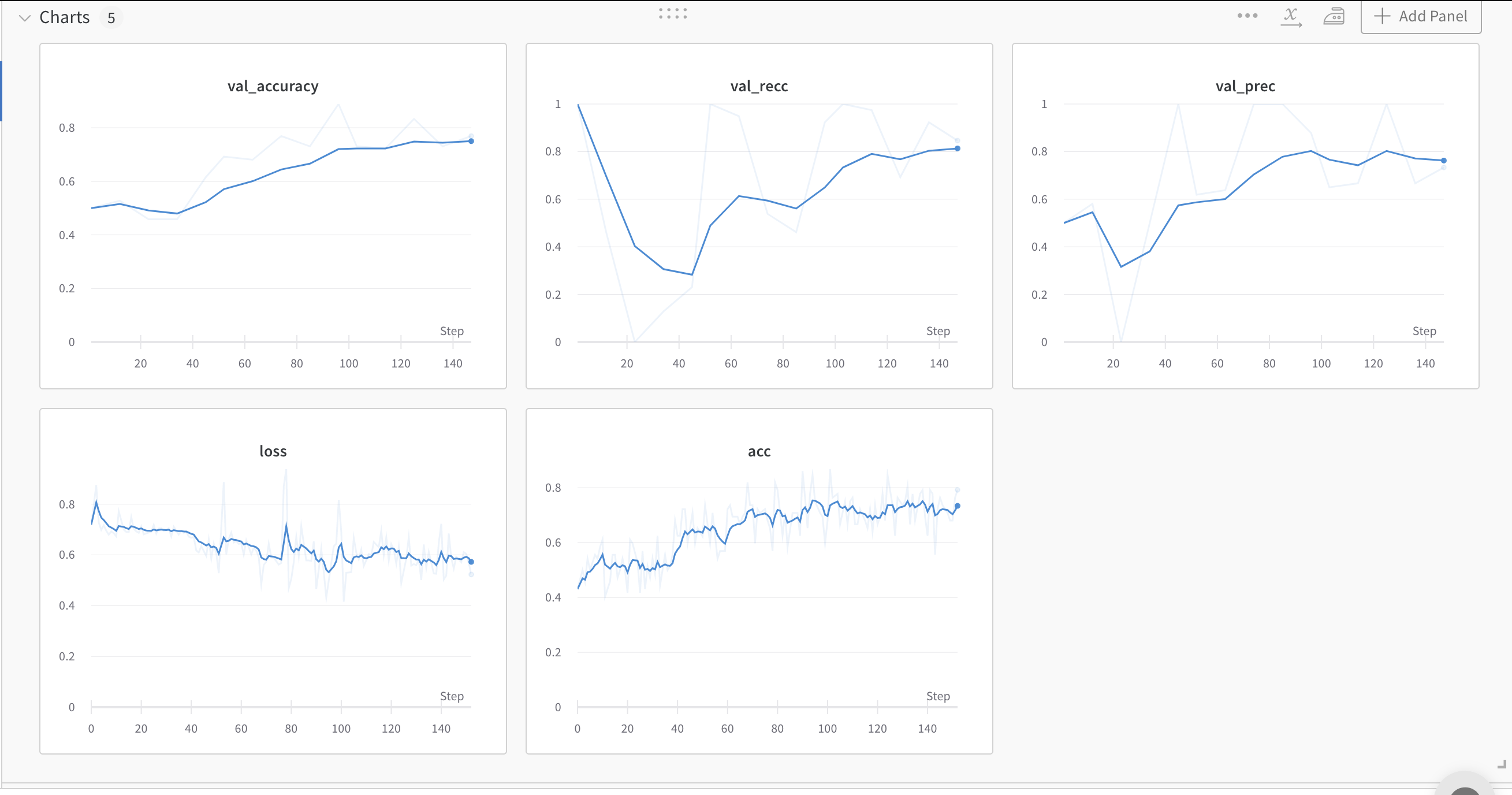
- Commentary: underfitting
- Dropping batch size down to 64 to add more steps
train: smart-river-14
{bs: 64, epochs: 3, lr: 1e-4, length: 60, cookiepitt-7-7-windowed-long-bal.dat}
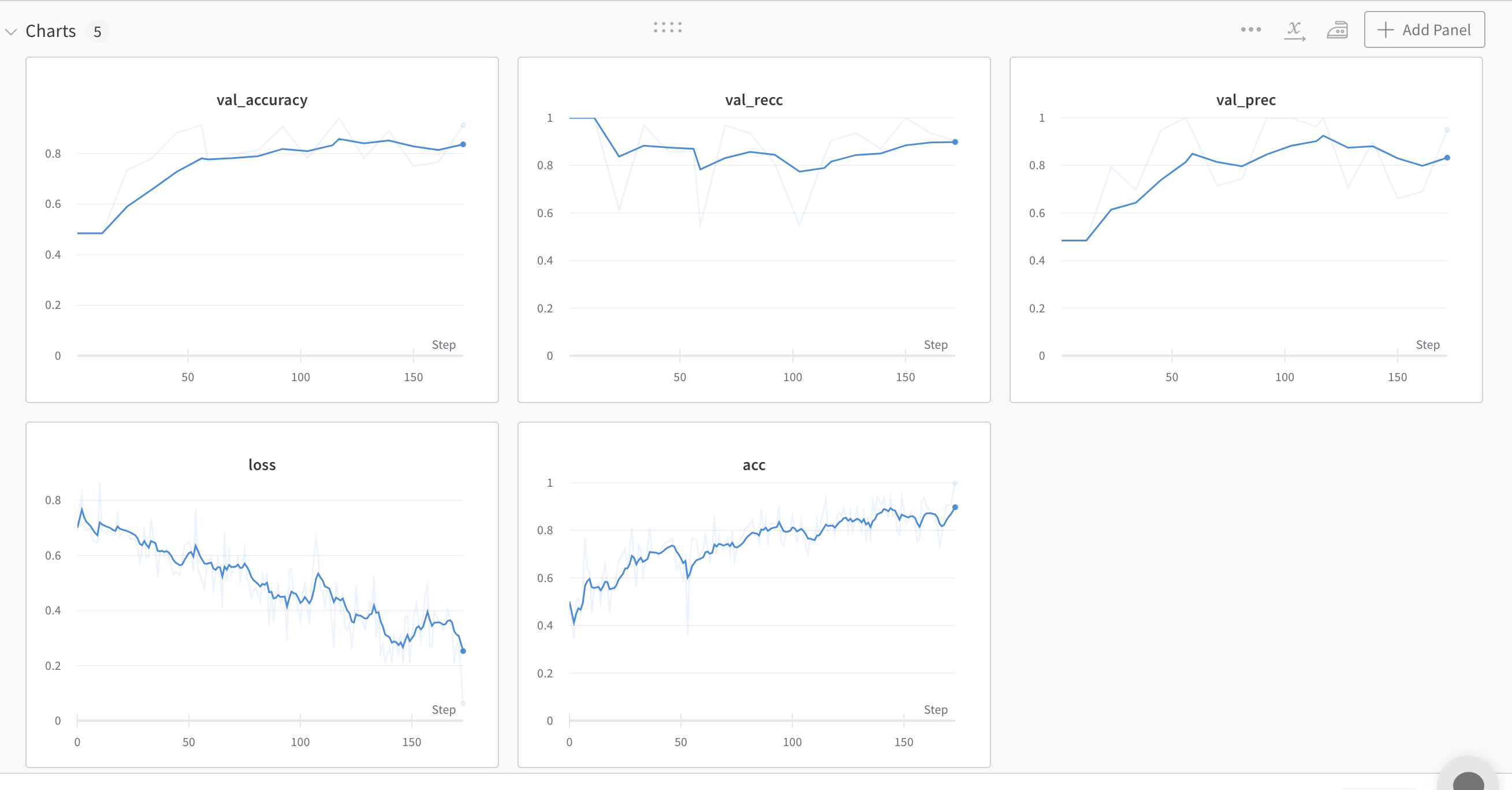
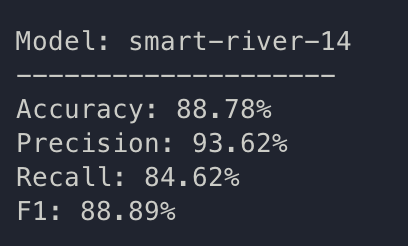
- Commentary: this finally fits to the specifications which Yuan 2021 have revealed
- Decision: running k-fold on this architecture
k-fold: XgsP4FVS6ScFxCZKFJoVQ5.
Code: 3870651ba71da8ddb3f481a7c3e046397a09d8b2

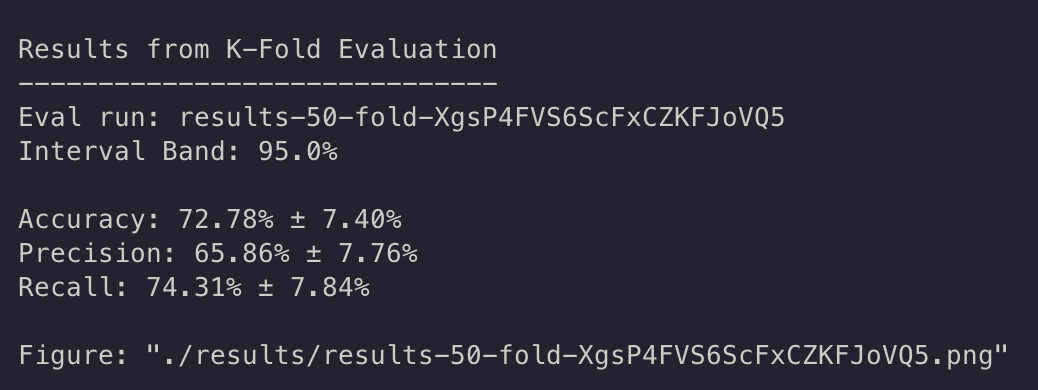
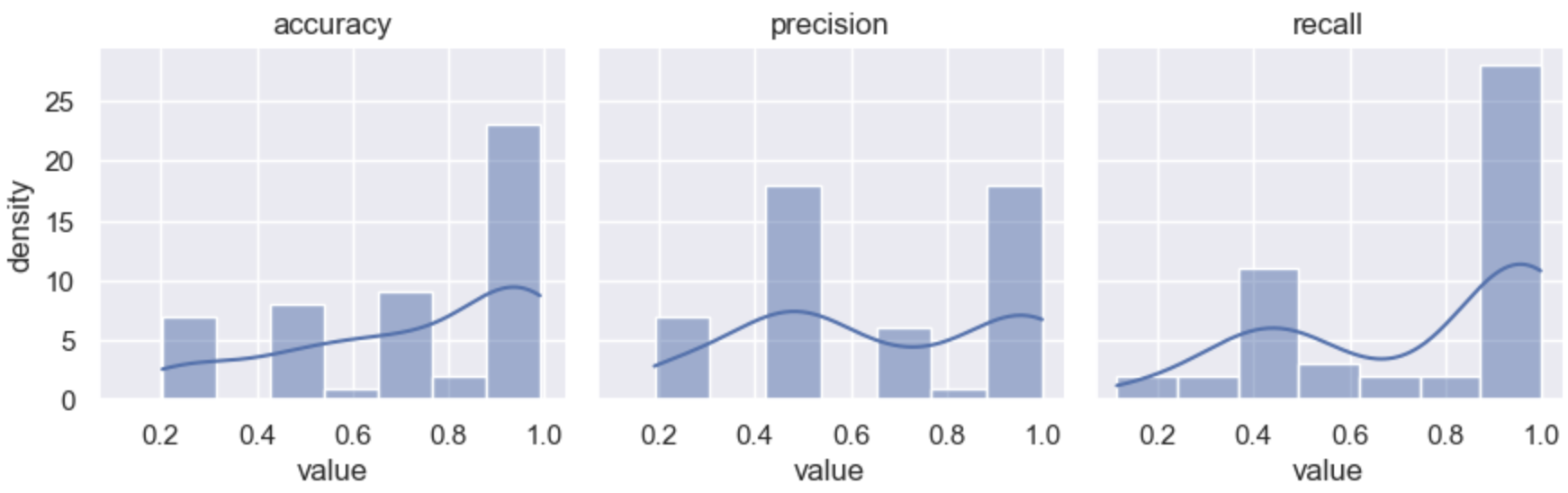
July 8th
Began the day with aligning the entirety of cookie for both control and dementia, named the dataset
alignedpitt-7-8in the RAW folderPer what we discussed, will add [pause] as a token to the model. Then, transcript the text such that it would contain normalized values to the pauses for pauses > 0.250 seconds. Therefore, the data would look like
“hello my name is [pause] 262 [pause] bob”
July 9th
- Created transcript.py, which coverts the data in
rawtotranscripts_pauses, which contains pause values > 250 msc and prepends them with [pause] tokens - The code from above is taken from
check.pyin batchalign, usedtranscript.pyfrom7e19a4912cf0ad5d269c139da5ce018615495ebbto clean out the dataset; placed it in similar txt format toalignedpitt-7-8 - Ran dataprep with window size of 5, created
alignedpitt-7-8.batandalignedpitt-7-8-windowed.batas the dataprep file - starting a new training run, with
[pause]added as a new token, code06846c6c95e6b1ccf17f0660c5da76aa50231567
train: golden-tree-16
{bs: 64, epochs: 3, lr: 1e-4, length: 60, alignedpitt-7-8-windowed.dat}
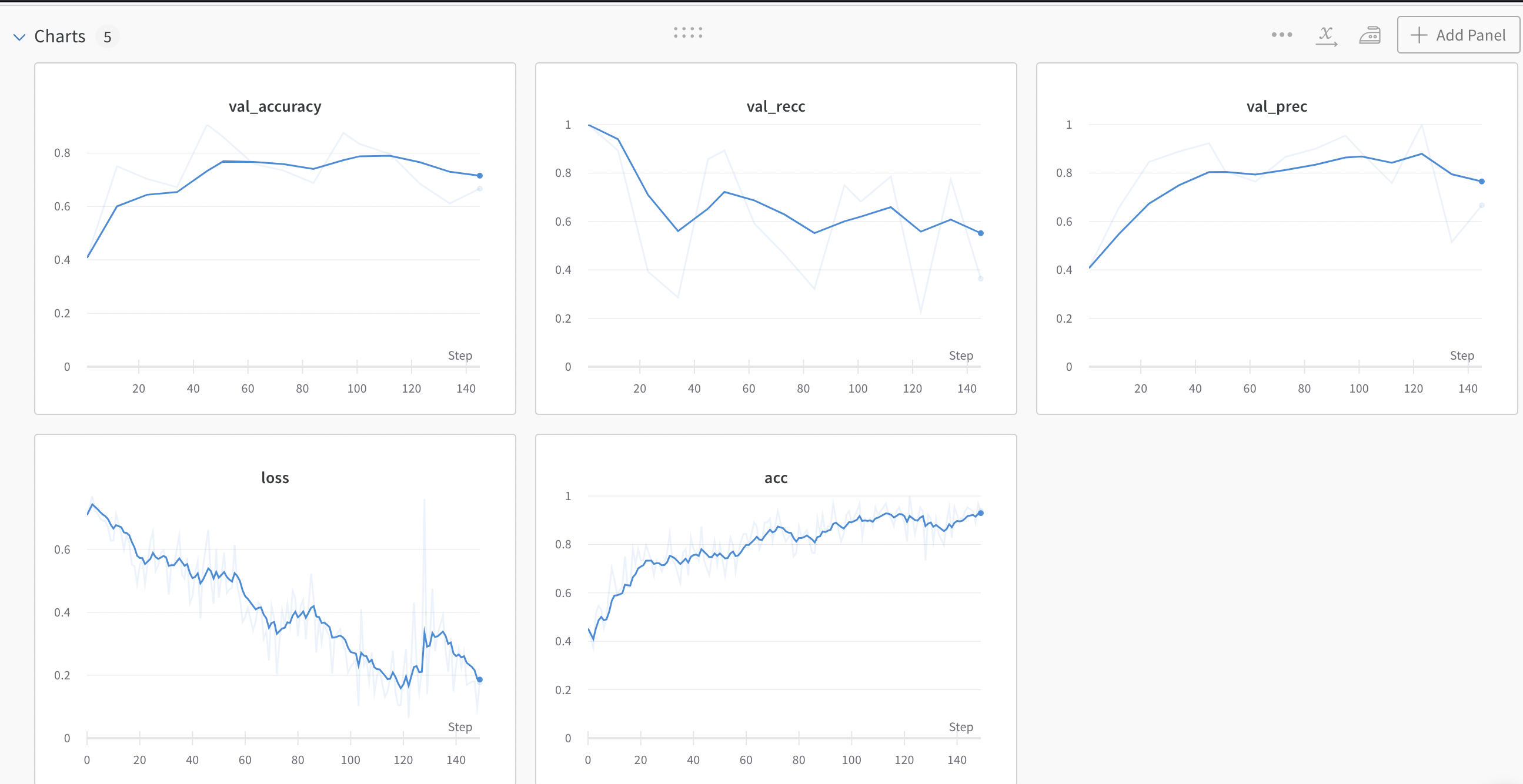
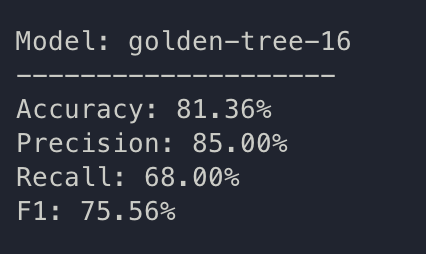
So realistically, we have the same F1 between the two, but pause encoding increased the accuracy of prediction yet dropped recall dramatically.
As a random check, let’s find out if simple fine-tuning (only training on classifier) would work, so:
train: jumping-blaze-17
{bs: 64, epochs: 3, lr: 1e-4, length: 60, alignedpitt-7-8-windowed.dat}. This time with only training classifier.
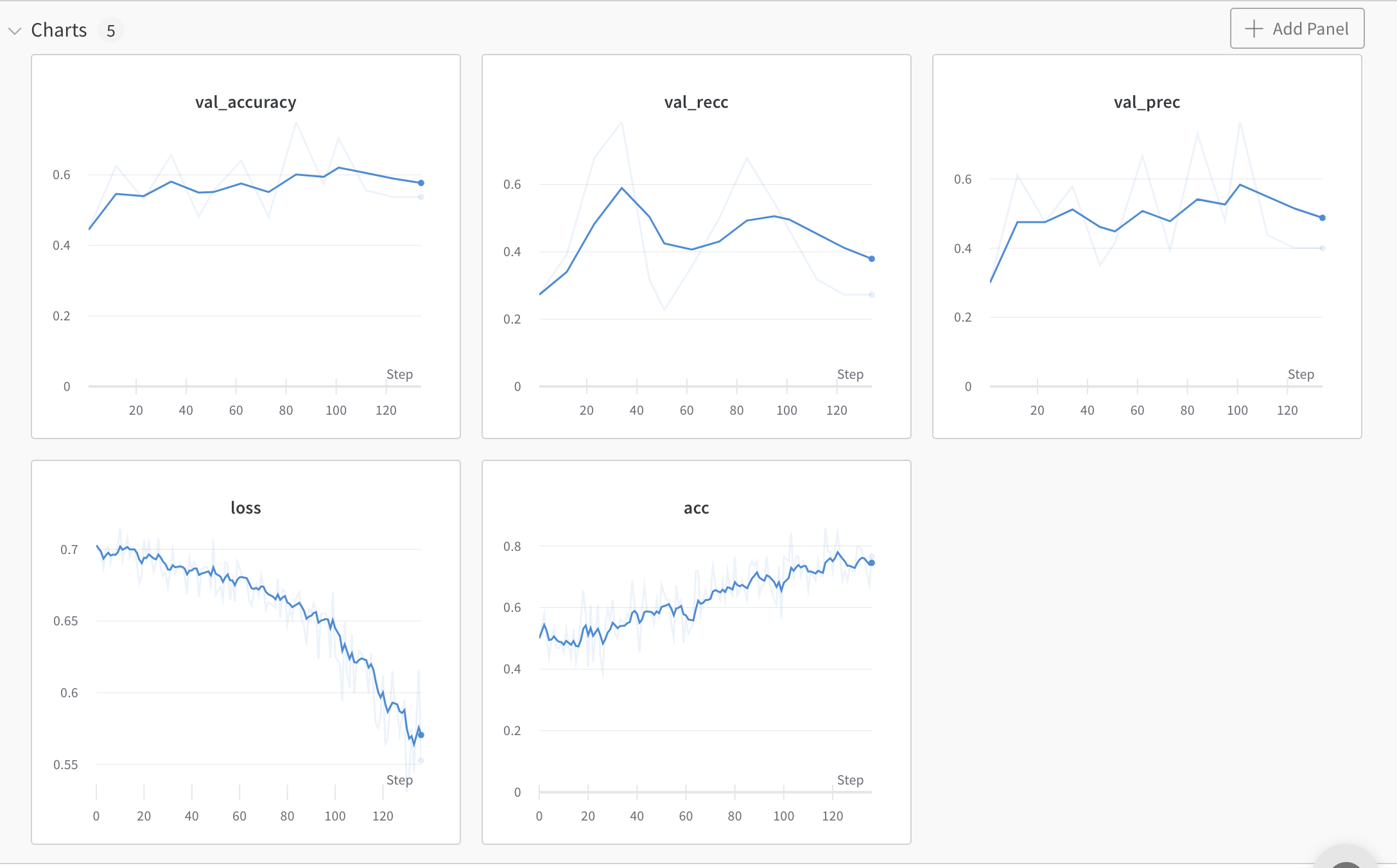
- Commentary: we did not like. start coverging
- Bumping LR by a factor of 10
train: vital-water-18
{bs: 64, epochs: 3, lr: 1e-3, length: 60, alignedpitt-7-8-windowed.dat}. This time with only training classifier.
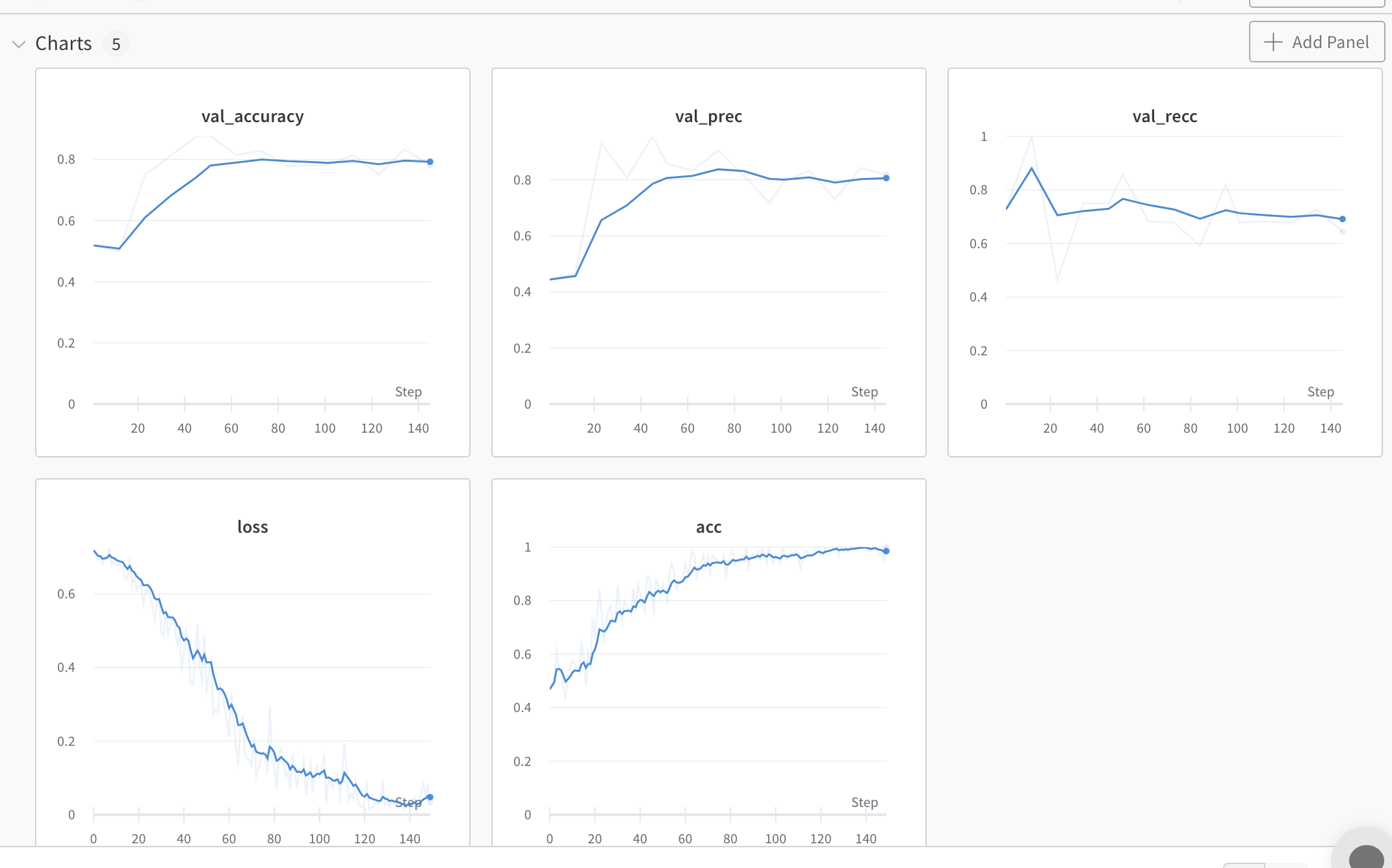
- Commentary: barely started converging, seem to be a local
- Training for 2 more epochs
train: fiery-smoke-19
{bs: 64, epochs: 5, lr: 1e-3, length: 60, alignedpitt-7-8-windowed.dat}. This time with only training classifier.
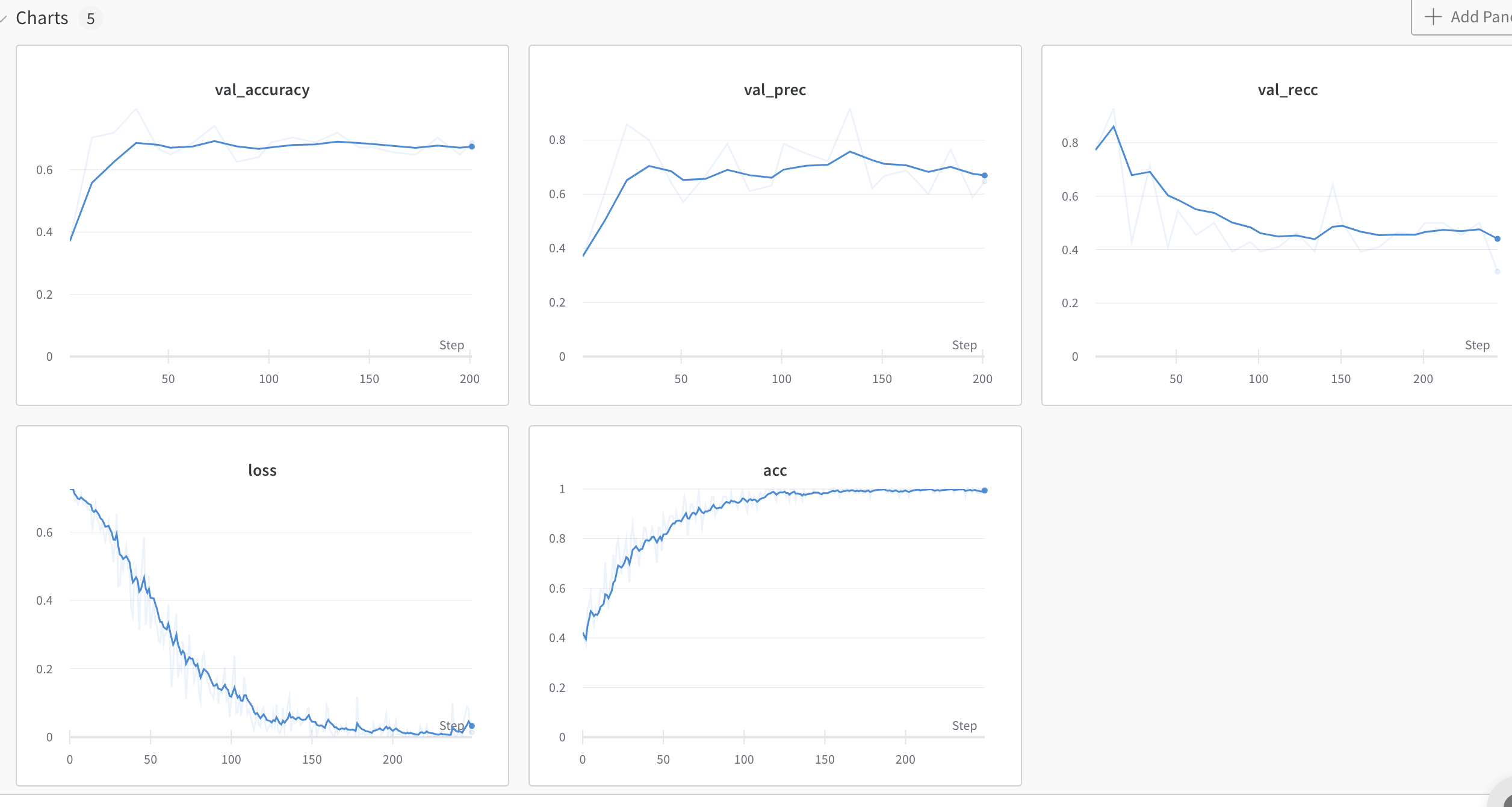
- Commentary: classic overfitting
At this point, unlocking the model would probably be a good bet
train: leafy-deluge-20
{bs: 64, epochs: 5, lr: 1e-4, length: 60, alignedpitt-7-8-windowed.dat}.
Training once again with code without locking, and bump LR down
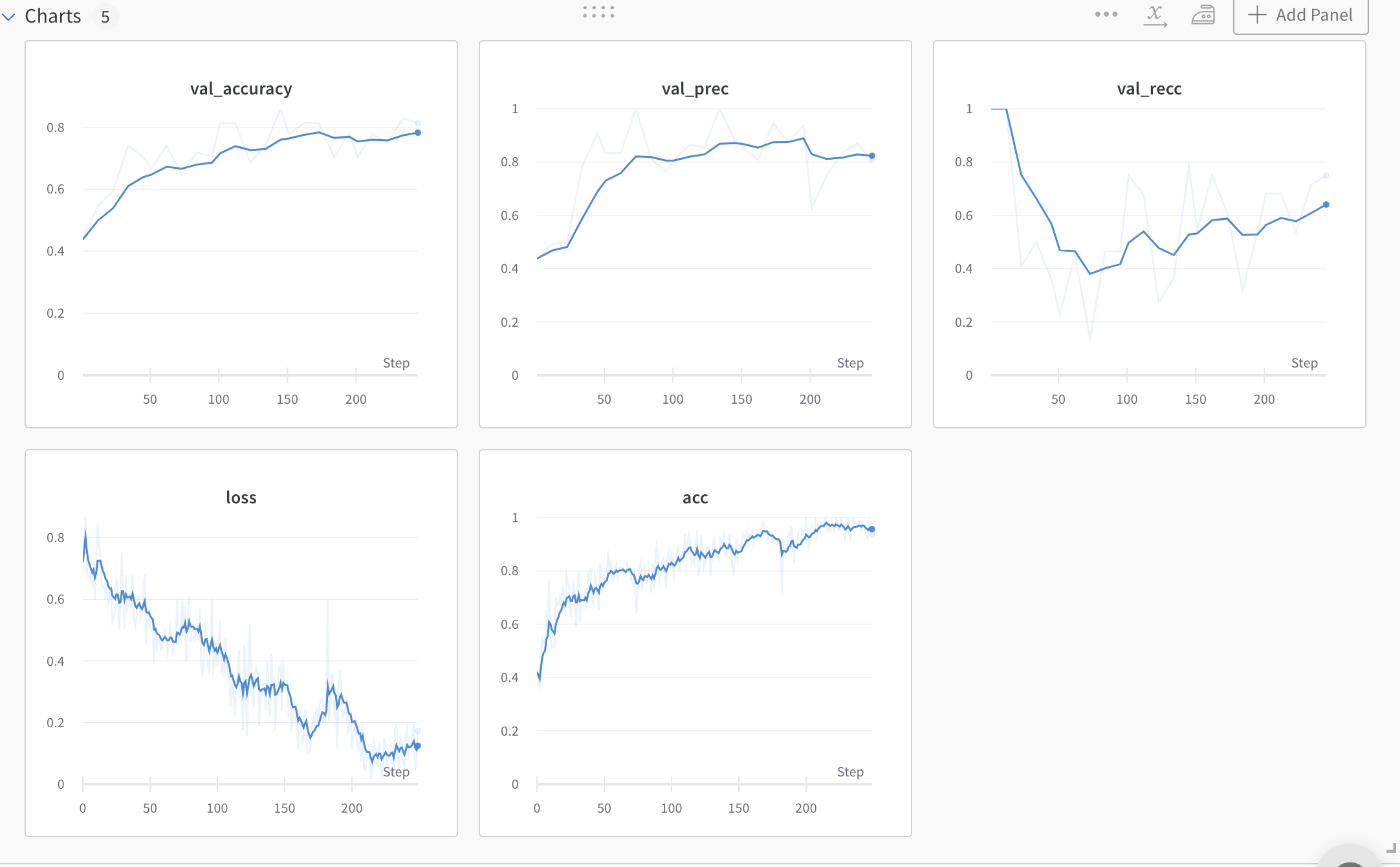
- Commentary: classic the recall is slowly creeping up
- Decision: let’s go for 8 epochs
train: royal-pond-21
{bs: 64, epochs: 8, lr: 1e-4, length: 60, alignedpitt-7-8-windowed.dat}.
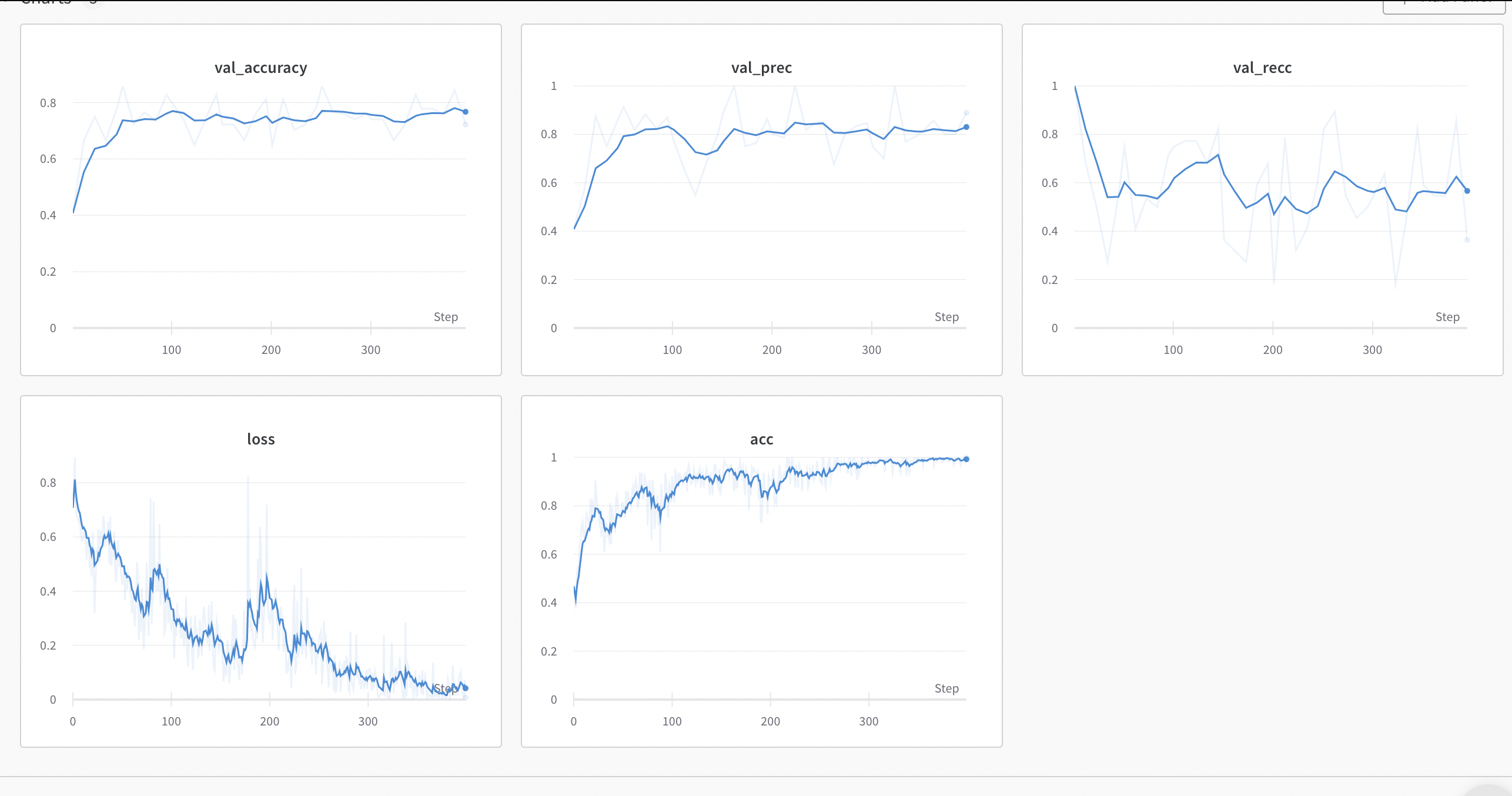
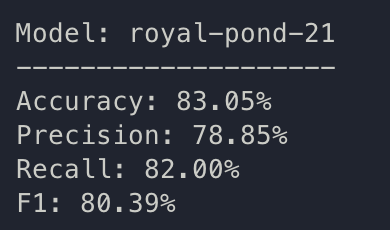
Commentary: let’s run k-fold now, with these settings.
k-fold: QskZWfEsML52ofcQgGujE2.

{bs: 64, epochs: 8, lr: 1e-4, length: 60, alignedpitt-7-8-windowed.dat}.
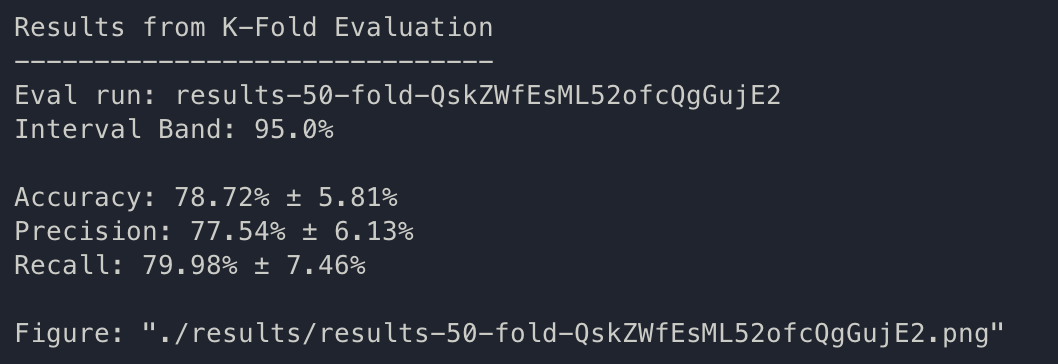
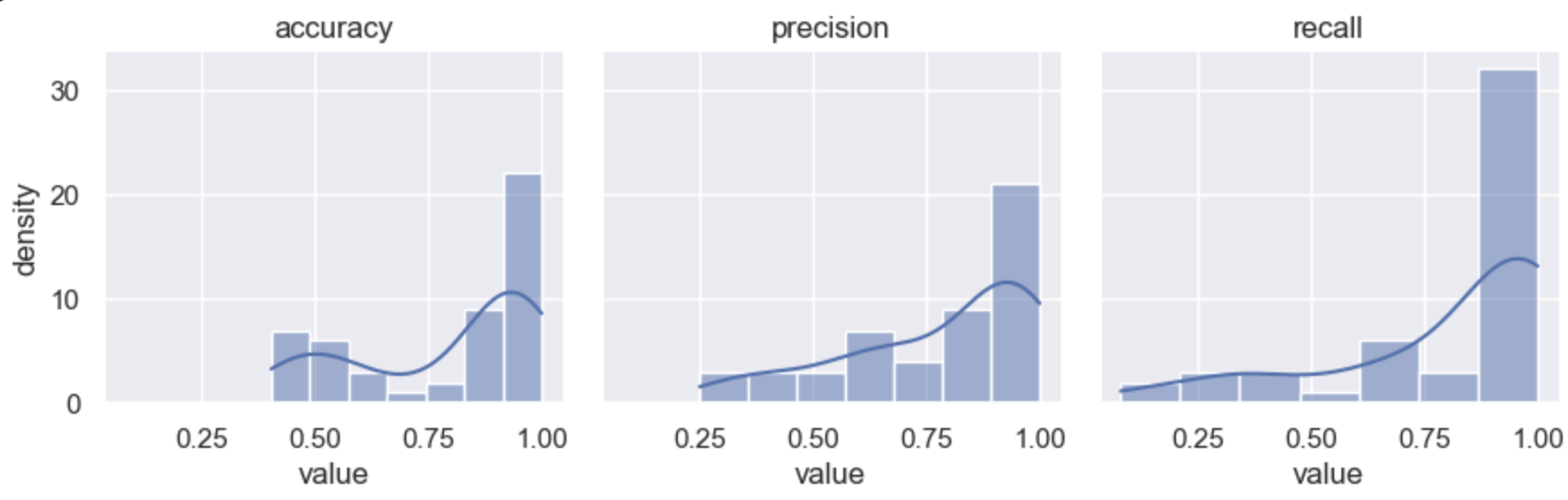
Ok, the base hypothesis from Yuan 2021 is very much confirmed here. The same training, same content, but pause encoding is very beneficial to the quality of the results. The results that they reported contained an ensemble data, which is in the high 80s; we can now continue doing something new as Yuan 2021’s conclusion is fairly achieved.

We can probably call the replication stage done, with no dramatically better effect.
July 10th
- FluCalc! Leonid’s lovely new program can be an uberuseful feature extraction tool
- Let’s try using to build a new dataset, and network. FluCalc + Pause Encoding + Textual Data late fusion
- This is becoming
alignedpitt-7-8-flucalc. As the program is currently under heavy development to include results from batchalign, we will specify versionV 09-Jul-2022 11:00for now. - Done, the new data has the same i/o shape, but then has a bunch of features filtered for nulls which contains outputs from flucalc. Again,
alignedpitt-7-8-flucalcfrom4346fc07c4707343c507e32786b6769b6bd6fb49does not take into account results from the%wortier!
July 11th
ab19abd6486884141c9ab4e4e185255a77ae833eis the final-ish version of the late fusion model- We are going to use
alignedpitt-7-8-flucalcto start training
train: royal-pond-21
{bs: 64, epochs: 8, lr: 1e-4, length: 60, alignedpitt-7-8-flucalc-windowed.dat}.
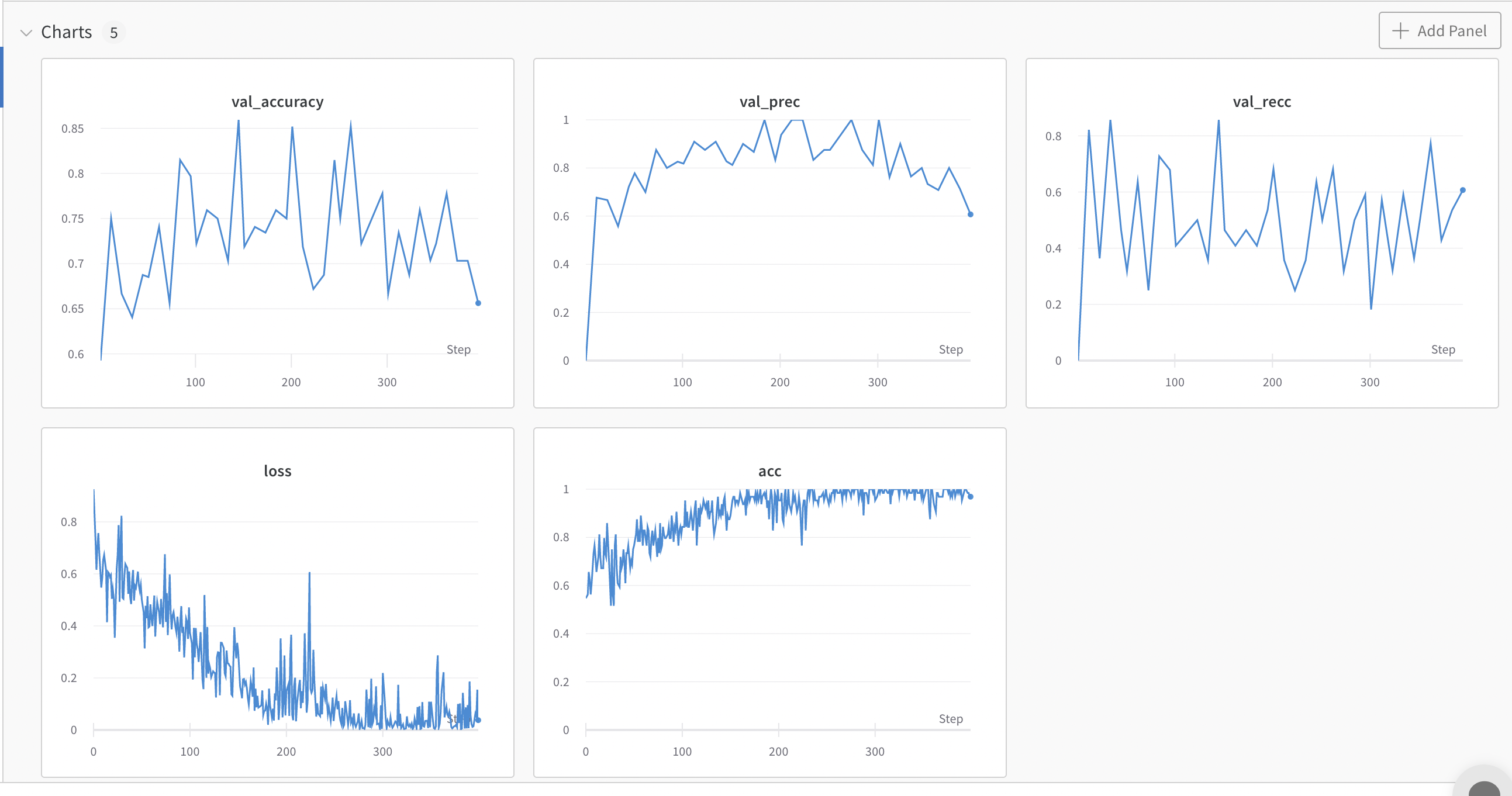
- Commentary: overfitting
- Decision, droping lr by a factor of 10, also increasing length to 70
train: fallen-dust-25
{bs: 64, epochs: 8, lr: 1e-5, length: 70, alignedpitt-7-8-flucalc-windowed.dat}.
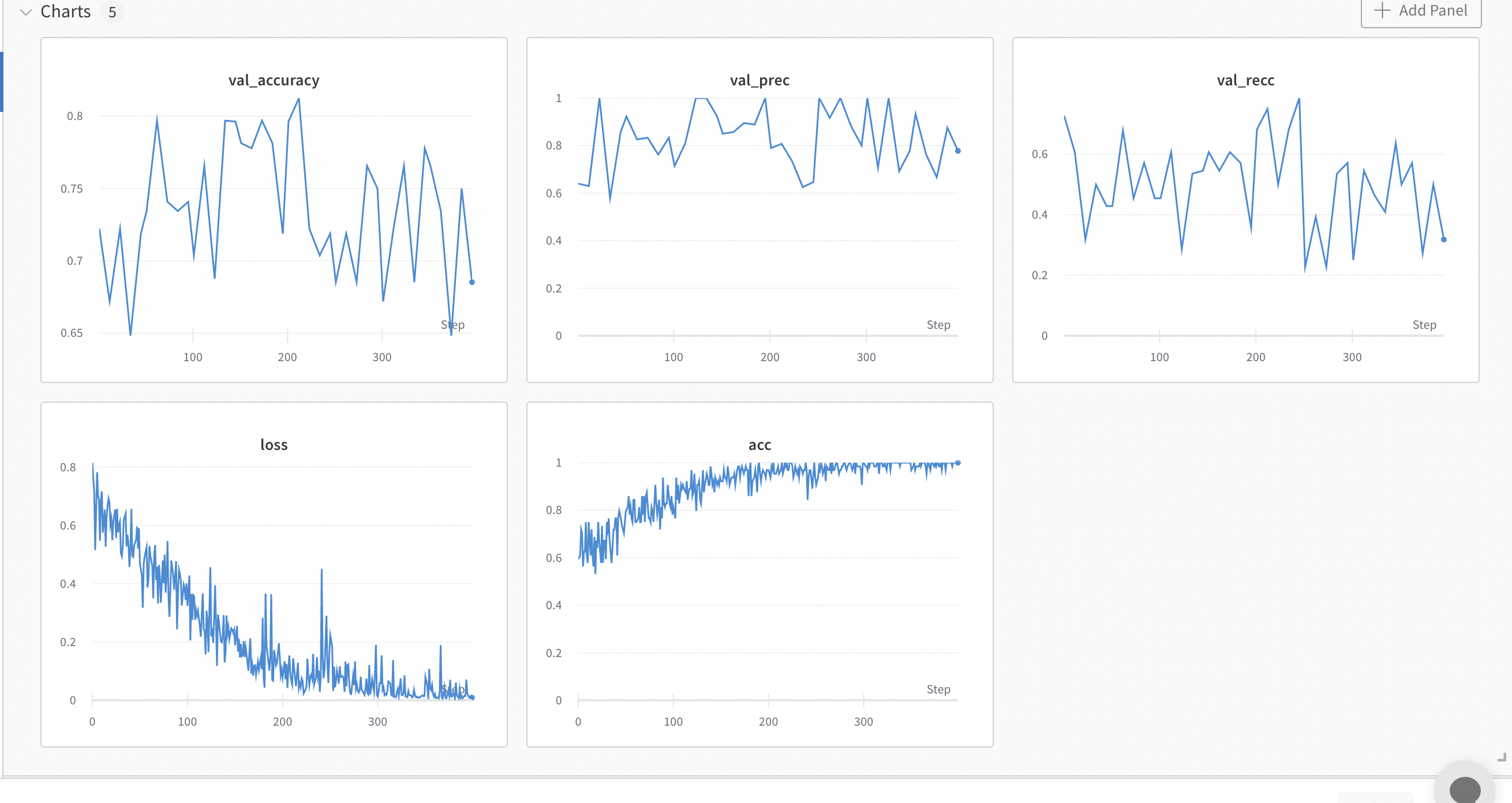
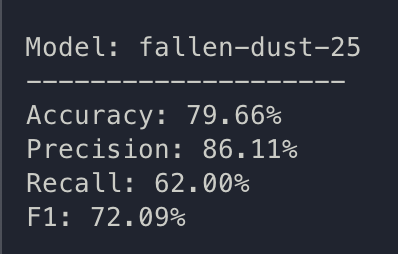
- Commentary: overfitting
- Decision, droping lr by a factor of 10, dropping batch size to 32, training more to 10
train: dainty-meadow-26
{bs: 32, epochs: 10, lr: 1e-6, length: 70, alignedpitt-7-8-flucalc-windowed.dat}.
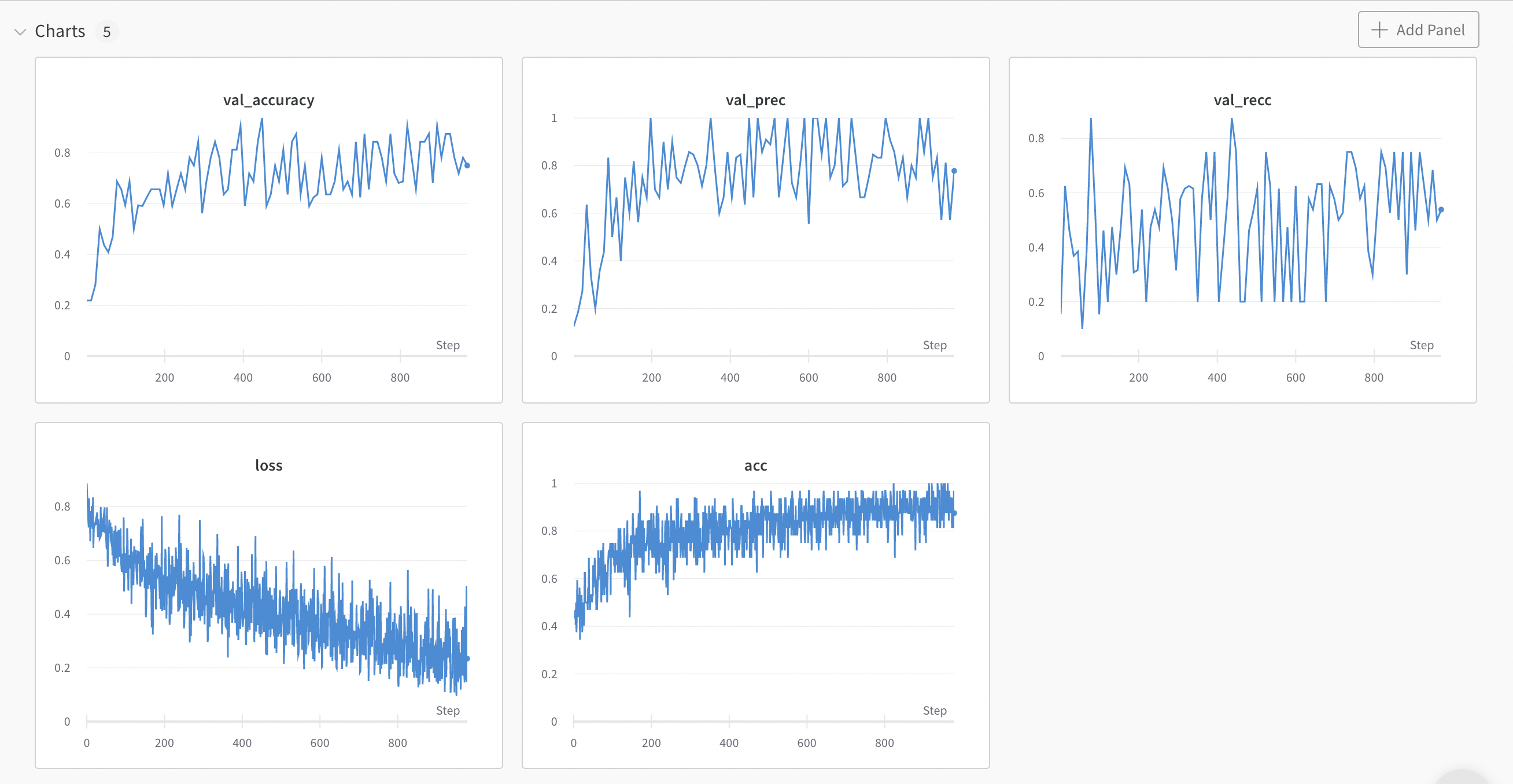
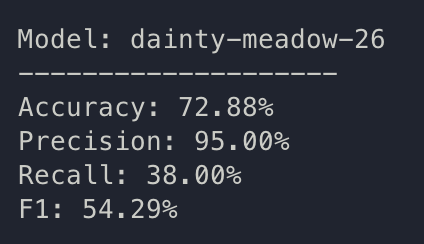
ah
- At this point, I think it’d be good to do some feature selection
- Let’s do a chi^2 correlation, and select 3 best features
import pandas as pd
DATA = "/Users/houliu/Documents/Projects/DBC/data/transcripts_pauses/alignedpitt-7-8-flucalc-windowed.bat"
# read pickle
df = pd.read_pickle(DATA)
# test
test_data = df[df.split=="test"]
# also, get only train data
df = df[df.split=="train"]
df
target mor_Utts ... split utterance
trial sample ...
120-2 1049 1 -0.179084 ... train well the boy is getting some cookies handing o...
336-1 2492 0 -0.481740 ... train +oh okay, the the little girl askin(g) for the...
076-4 786 1 -0.179084 ... train well the little boy was looking at that cookie...
279-0 2250 1 1.980274 ... train kid's stool turnin(g) [pause]540[pause] over s...
014-2 151 1 0.746355 ... train he's fallin(g) off the chair down here or try...
... ... ... ... ... ...
208-0 1655 0 -0.481740 ... train the boy [pause]920[pause] is going after [paus...
492-0 2696 1 -0.179084 ... train oh yes quite a_lot the kid's tryin(g) to get t...
497-1 2727 1 0.129396 ... train what else ? &uh the see the [pause]2400[pause]...
175-2 1535 0 0.863668 ... train the window is open you can see out the curtain...
279-0 2261 1 1.980274 ... train the other kid with [pause]610[pause] the stool...
[2848 rows x 44 columns]
Let’s slice out the bits which is labels, etc.
in_data = df.drop(columns=["utterance", "target", "split"])
in_data.columns
Index(['mor_Utts', 'mor_Words', 'mor_syllables', '#_Prolongation',
'%_Prolongation', '#_Broken_word', '%_Broken_word', '#_Block',
'%_Block', '#_PWR', '%_PWR', '#_PWR-RU', '%_PWR-RU', '#_WWR', '%_WWR',
'#_mono-WWR', '%_mono-WWR', '#_WWR-RU', '%_WWR-RU', '#_mono-WWR-RU',
'%_mono-WWR-RU', 'Mean_RU', '#_Phonological_fragment',
'%_Phonological_fragment', '#_Phrase_repetitions',
'%_Phrase_repetitions', '#_Word_revisions', '%_Word_revisions',
'#_Phrase_revisions', '%_Phrase_revisions', '#_Pauses', '%_Pauses',
'#_Filled_pauses', '%_Filled_pauses', '#_TD', '%_TD', '#_SLD', '%_SLD',
'#_Total_(SLD+TD)', '%_Total_(SLD+TD)', 'Weighted_SLD'],
dtype='object')
And the labels:
out_data = df["target"]
out_data
trial sample
120-2 1049 1
336-1 2492 0
076-4 786 1
279-0 2250 1
014-2 151 1
..
208-0 1655 0
492-0 2696 1
497-1 2727 1
175-2 1535 0
279-0 2261 1
Name: target, Length: 2848, dtype: int64
And now, let’s select 3 best features.
from sklearn.feature_selection import SelectKBest, f_classif
k_best_tool = SelectKBest(f_classif, k=3)
k_best_tool.fit(in_data, out_data)
best_features = k_best_tool.get_feature_names_out()
best_features
| %_WWR | %_mono-WWR | %Total(SLD+TD) |
OD = other disfluencies; SLD = stuttering-like disfluencies; TD = total disfluencies; WWR = whole-word-repetition
ok, let’s select those features
train: visionary-plasma-27
{bs: 32, epochs: 10, lr: 1e-6, length: 70, alignedpitt-7-8-flucalc-windowed.dat}. Also with feature selection.
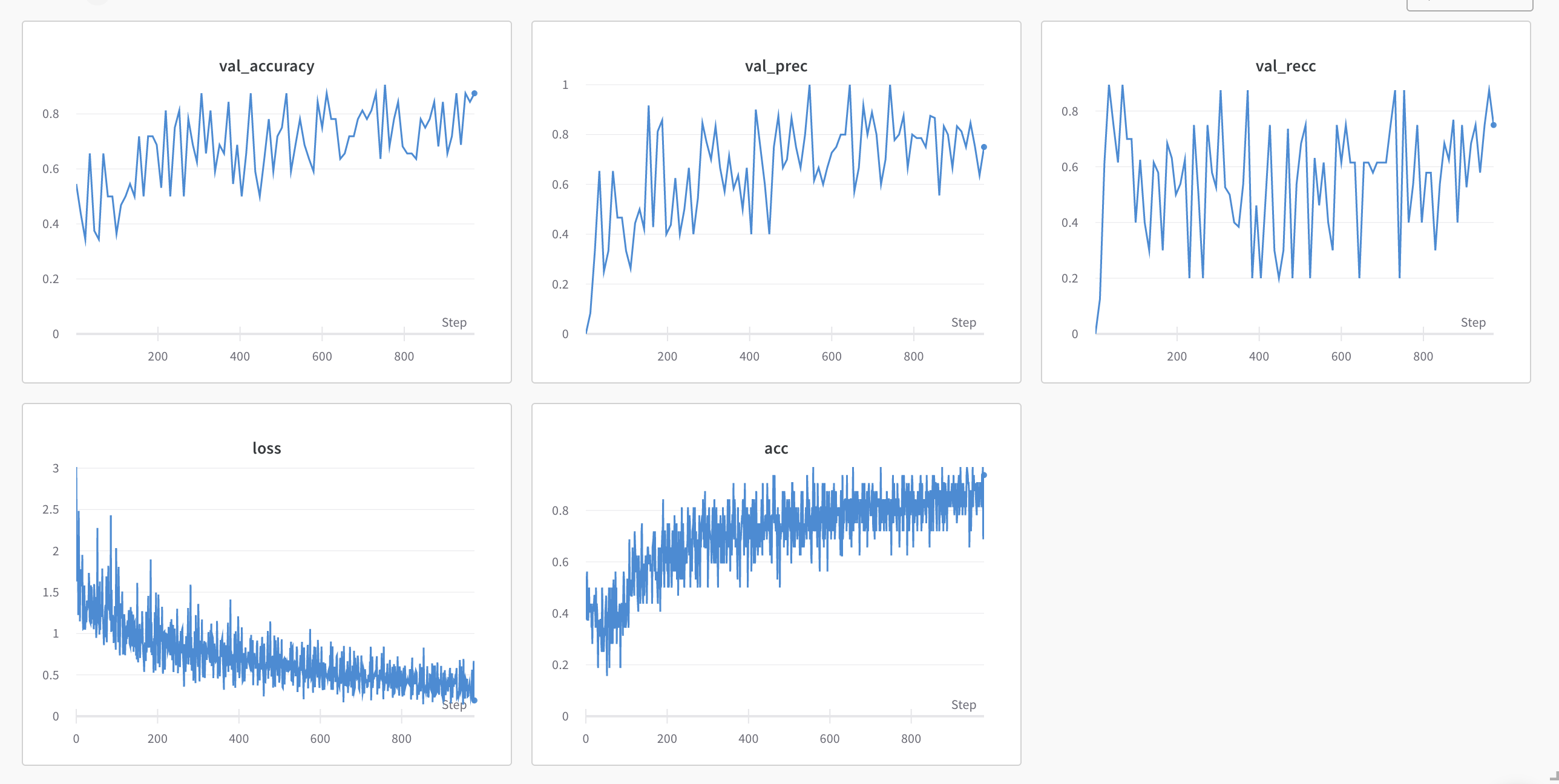
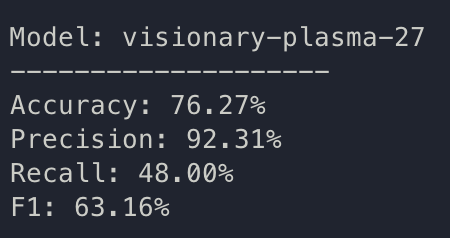
hmmm.
I am curious if we just ran something like a decision tree, what happens.
in_features = df.drop(columns=["utterance", "target", "split"])
test_features = test_data.drop(columns=["utterance", "target", "split"])
in_targets = df["target"]
test_targets = test_data["target"]
seed the classifier, and fit.
from sklearn.ensemble import RandomForestClassifier
clsf = RandomForestClassifier()
clsf.fit(in_features, in_targets)
clsf.score(test_features, test_targets)
0.5932203389830508
OK nevermind. What about SVC?
from sklearn.svm import SVC
clsf = SVC()
clsf.fit(in_features, in_targets)
clsf.score(test_features, test_targets)
0.5932203389830508
Turns out, deep learning still does better. I’m thinking maybe the output is being faulty, say, for something like the loss function.
Decision: switching activation to sigmoid.
train: sunny-bush-31
{bs: 32, epochs: 10, lr: 1e-6, length: 70, alignedpitt-7-8-flucalc-windowed.dat}, selected features
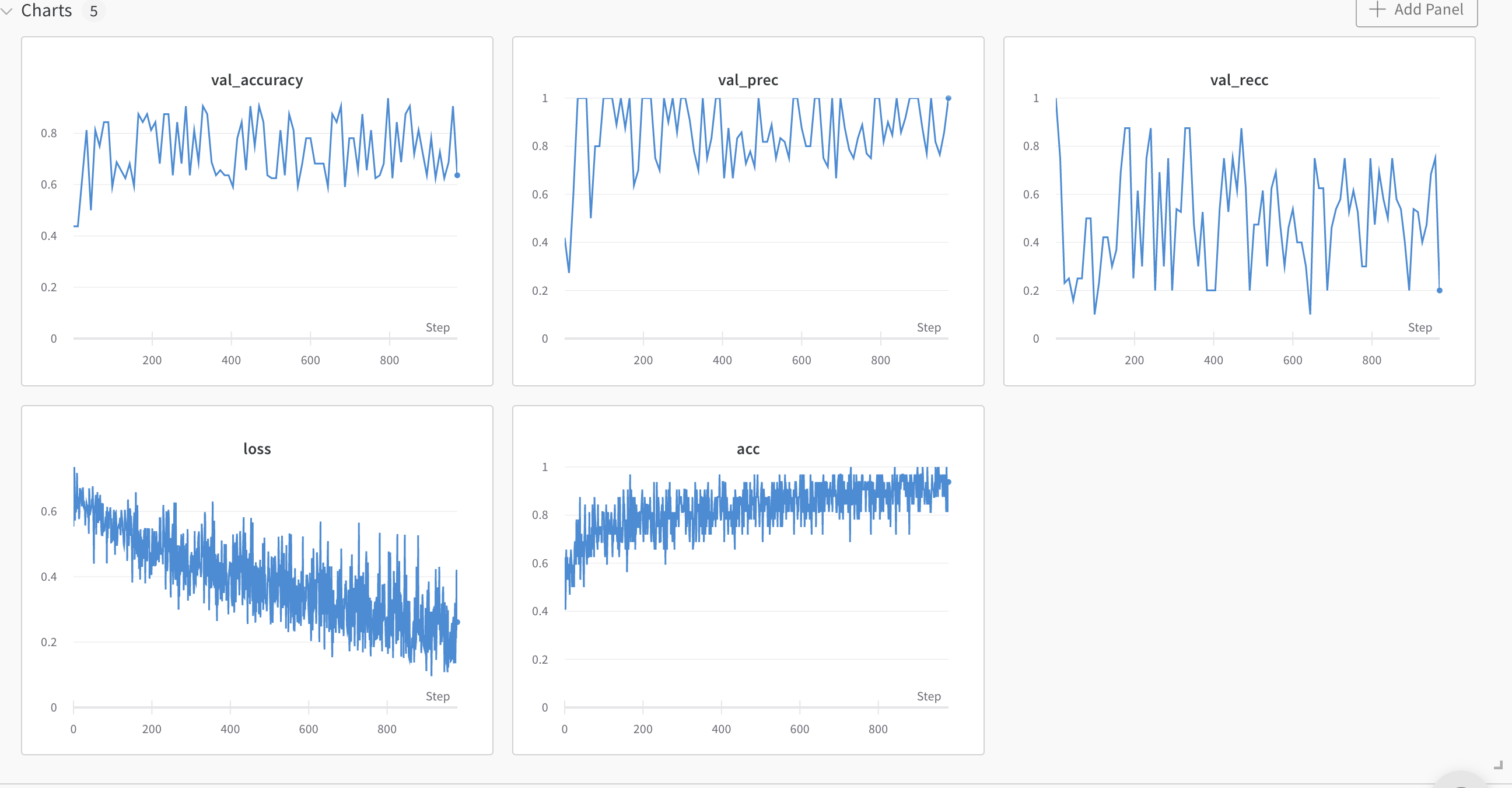
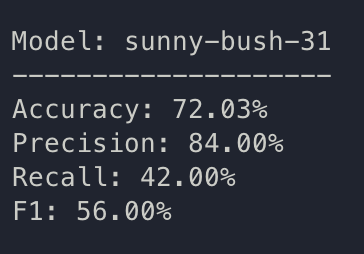
Ok let’s think about this. Decision: added batch normalization.
train: autumn-jazz-32
{bs: 32, epochs: 10, lr: 1e-6, length: 70, alignedpitt-7-8-flucalc-windowed.dat}, selected features
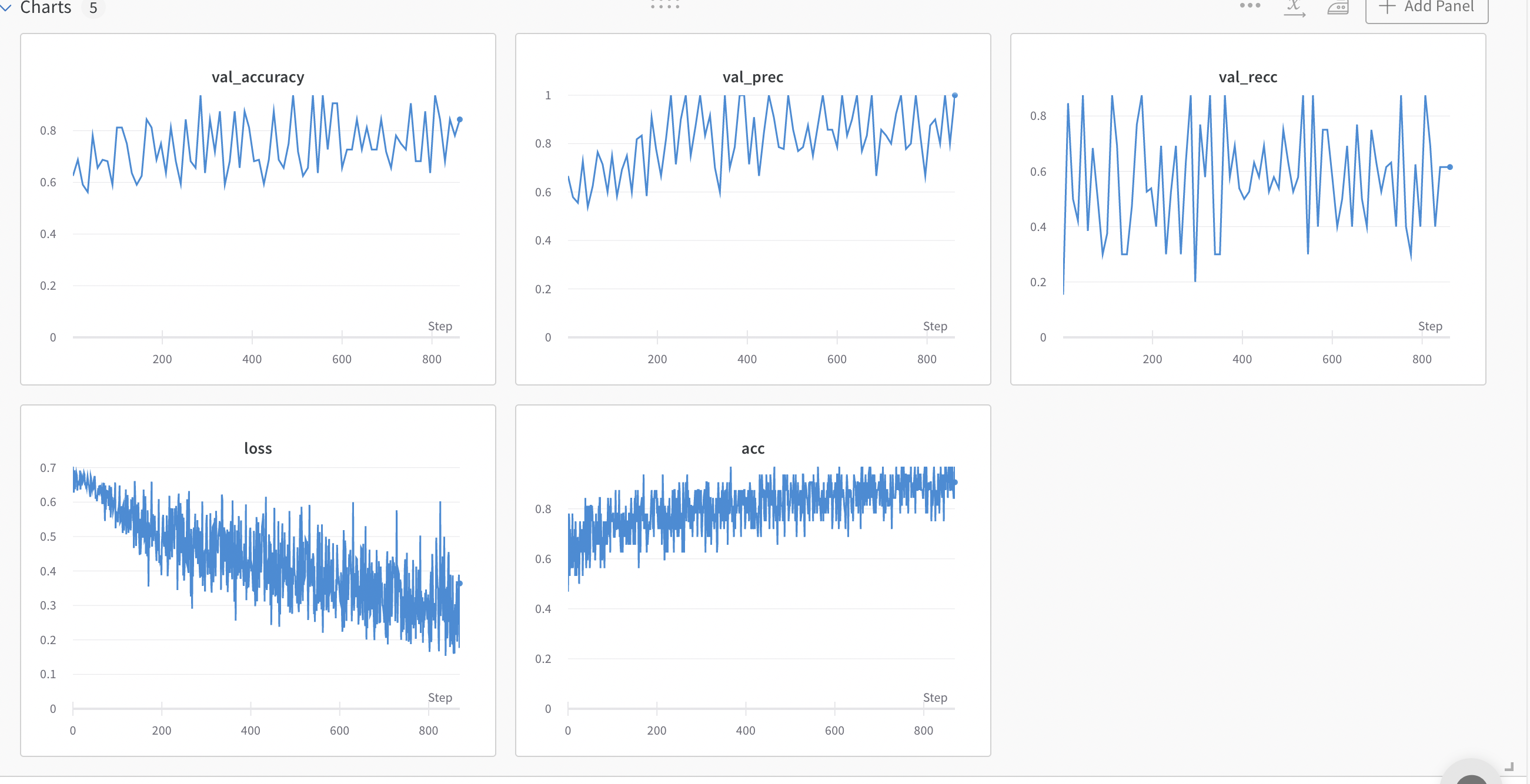
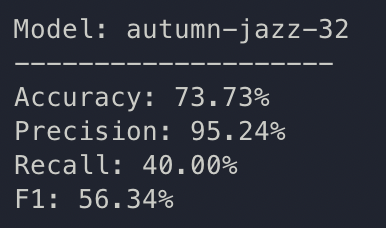
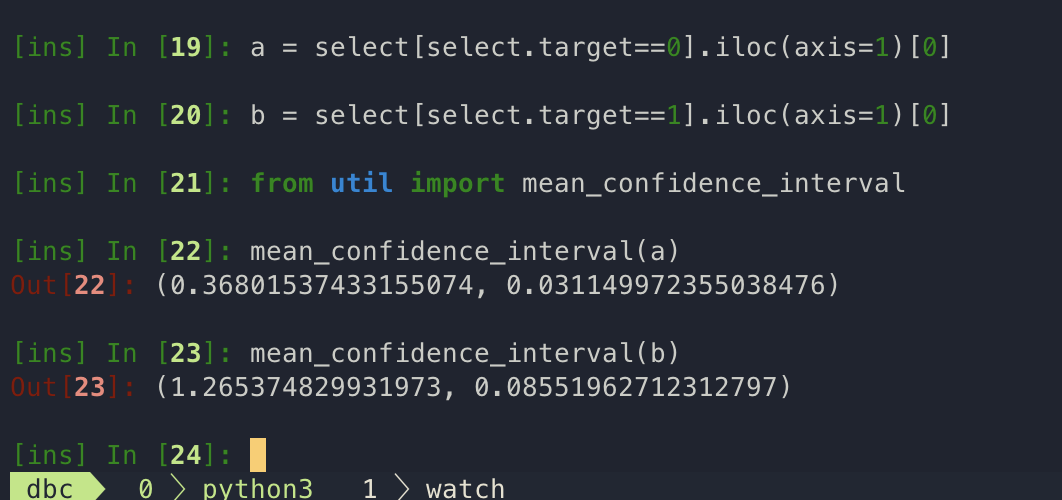
The model maybe overfitting on some simple heuristic; some basic statistics revealed that these variables are actually quite differently distributed.
Perhaps we should increase the complexity of the model?

train: fallen-microwave-33
{bs: 32, epochs: 10, lr: 1e-6, length: 70, alignedpitt-7-8-flucalc-windowed.dat}, selected features
Just to test, I am bumping the LR to 1e-5, just to see what happens. I am very confused.
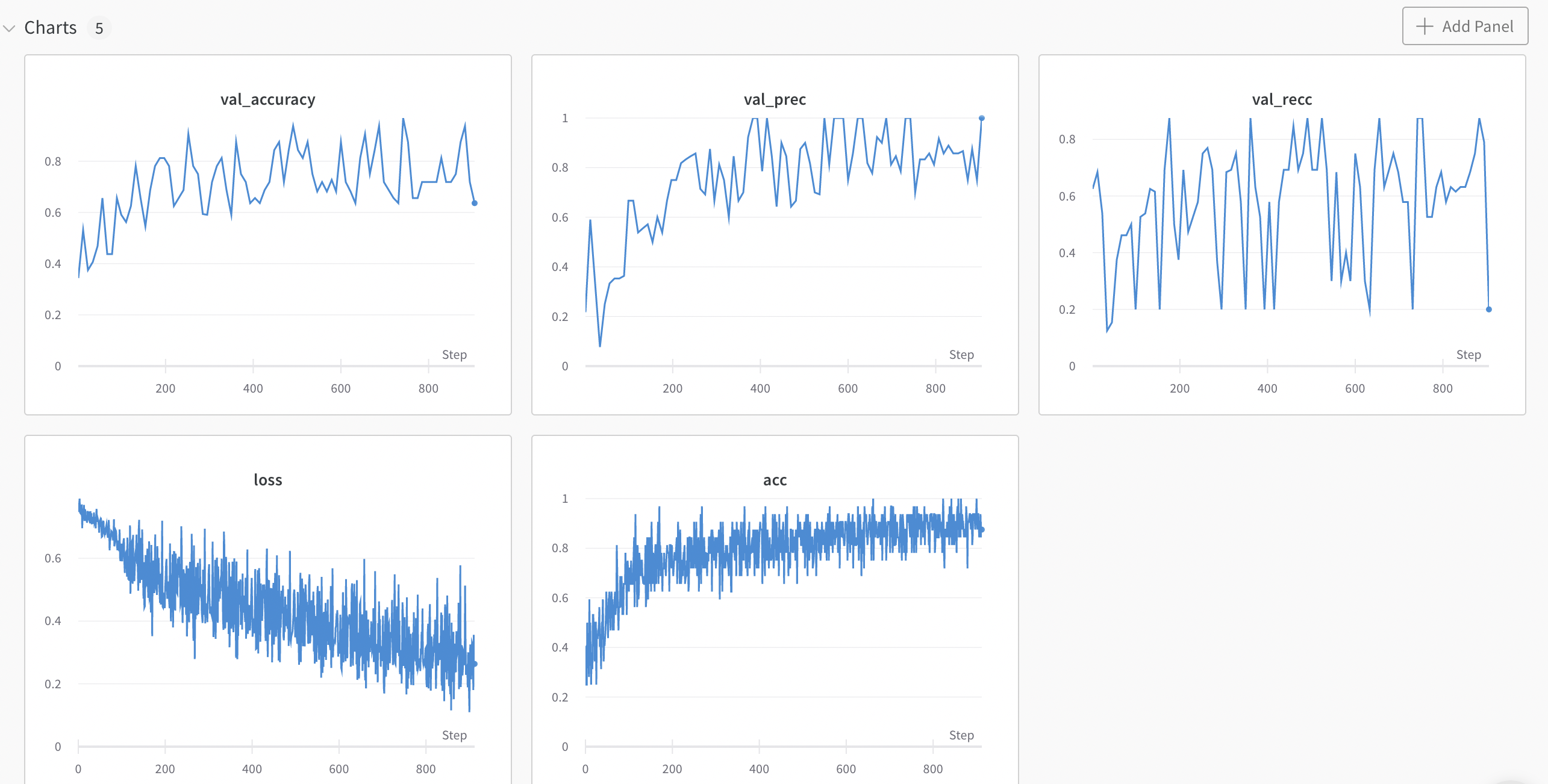
train: upbeat-flower-35
{bs: 32, epochs: 10, lr: 1e-5, length: 70, alignedpitt-7-8-flucalc-windowed.dat}, selected features
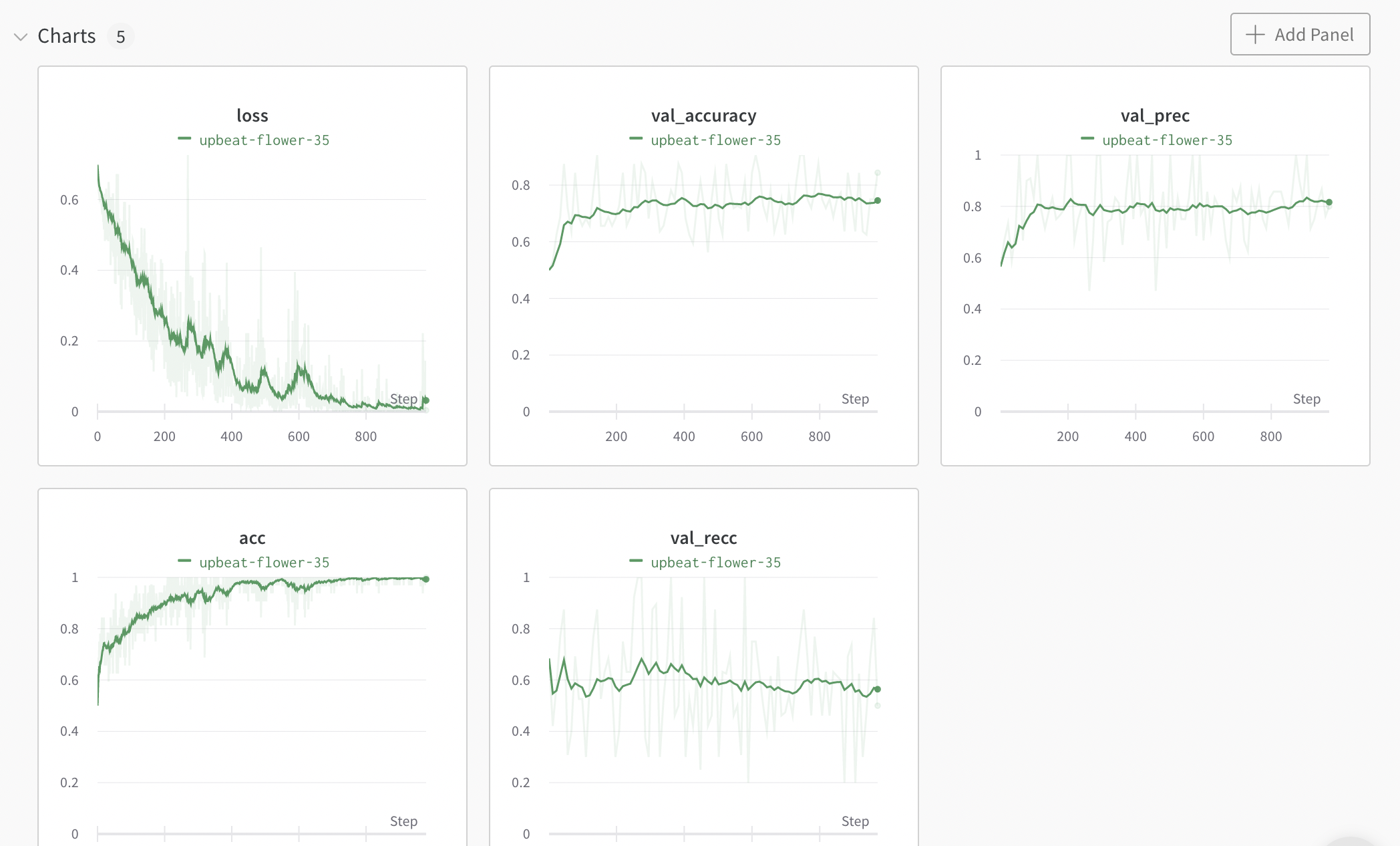
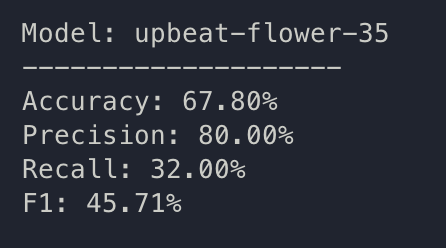
The more we work on this, the more overfit it gets. (I FORGOT A RELUCTIFIER)
a note
{bs: 32, epochs: 10, lr: 1e-5, length: 70, alignedpitt-7-11-flucalc-windowed.dat}, selected features
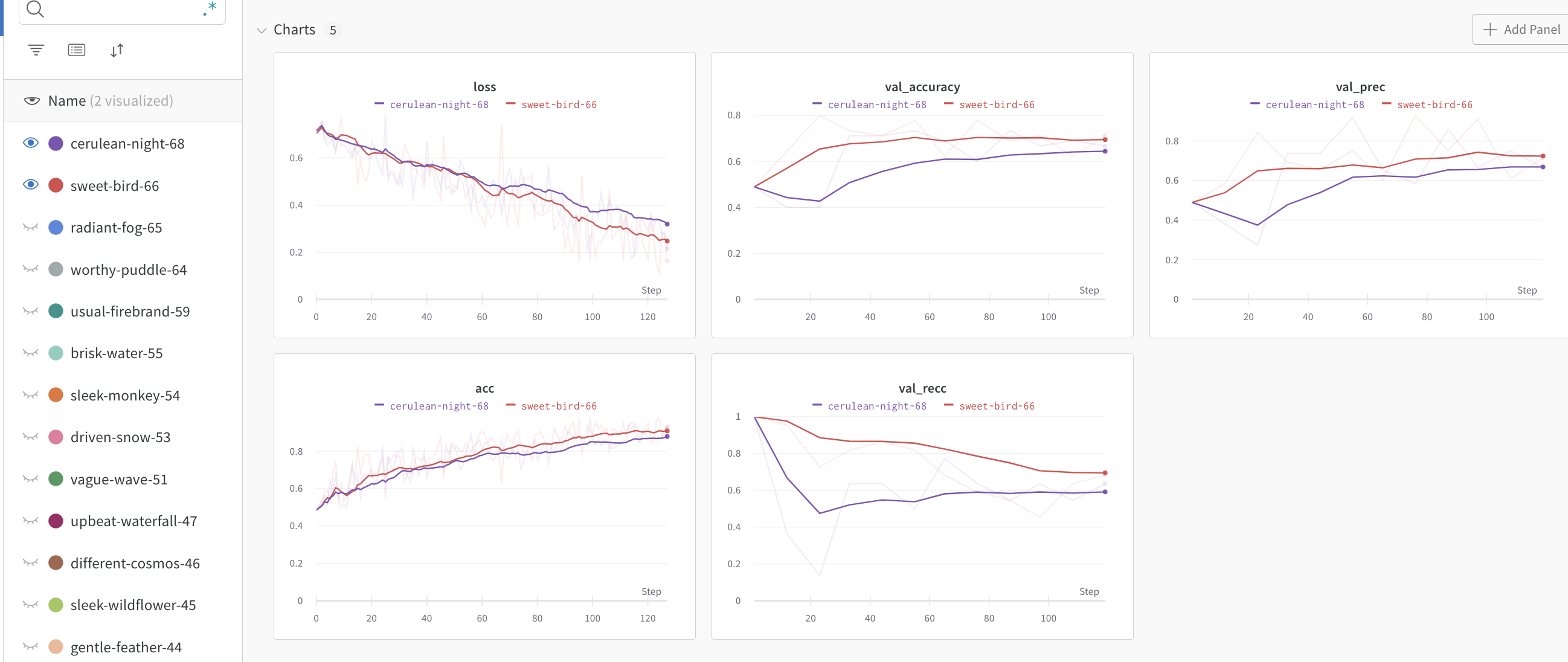
Pauses, no meta:
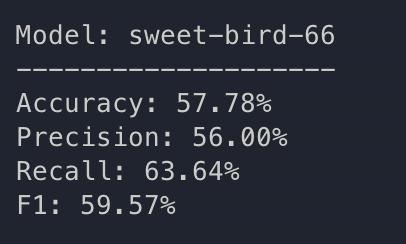
Pauses, meta:
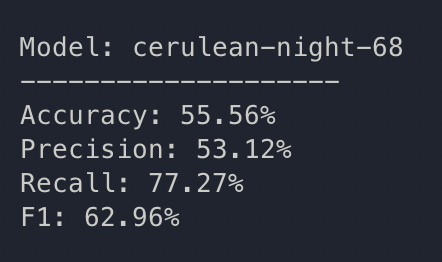
so effectively cointoss
Concerns and Questions
July 2nd
pitt7-1/dementia/493-0PAR tier “tell me everything you see going on in that picture” doesn’t seem to be labeled correctly; I am guessing that’s supposed to be INV?- Has anyone tried to include investigator/participant cross-dialogue?
July 4th
- Is the model overfitting on antiquated language?
- Is the model overfitting on cooke-theft on-topic-ness?
July 11th
- LSTM only on pauses?