Dialogue State Architecture uses dialogue acts instead of simple frame filling to perform generation; used currently more in research.
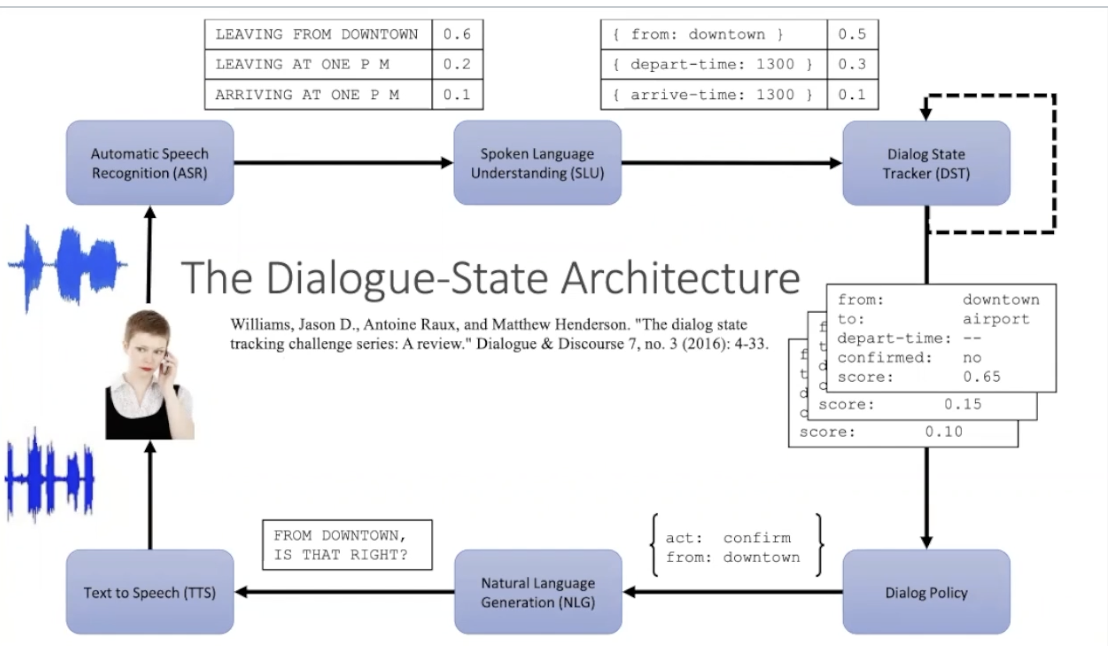
- NLU: slot fillers to extract user’s utterance, using ML
- Dialogue State Tracker: maintains current state of dialogue
- Dialogue policy: decides what to do next (think GUS’ policy: ask, fill, respond)—but nowaday we have more complex dynamics
- NLG: respond
dialogue acts
dialogue acts combines speech-acts with underlying states
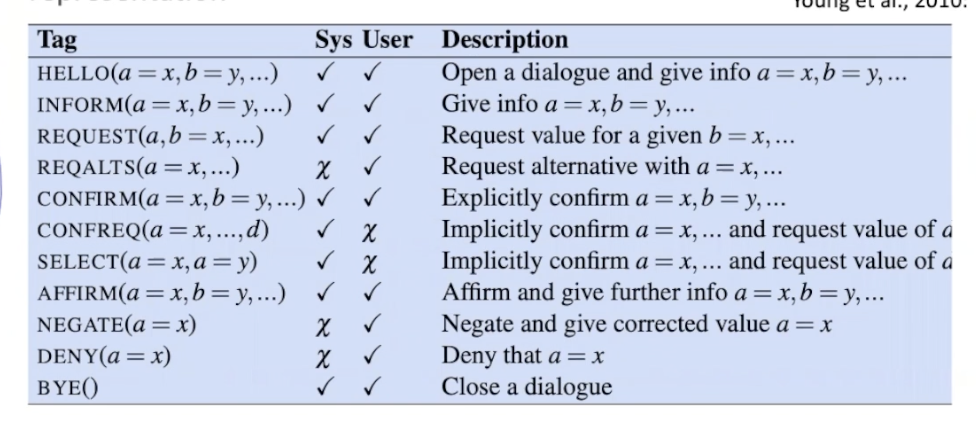
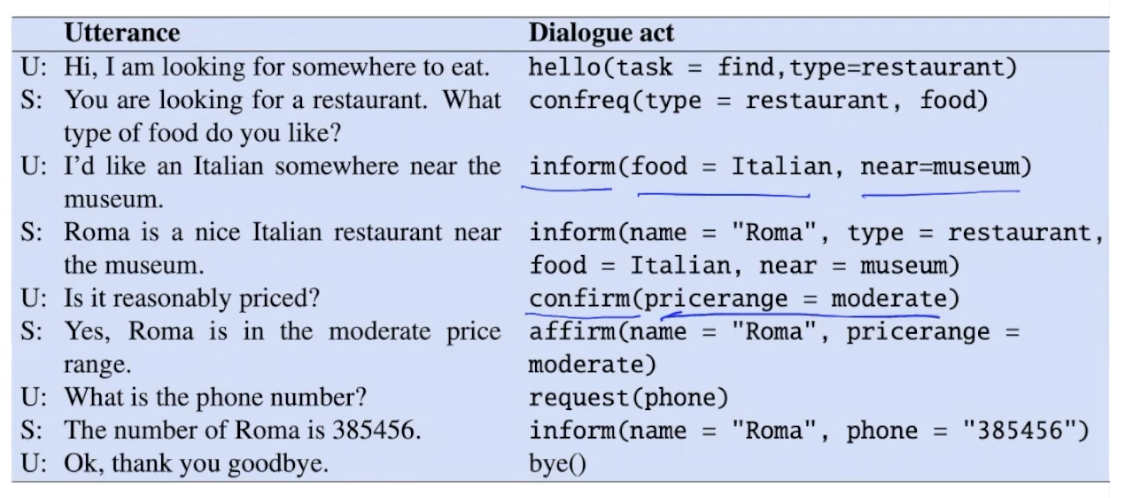
slot filing
we typically do this with BIO Tagging with a BERT just like NER Tagging, but we tag for frame slots.
the final <cls> token may also work to classify domain + intent.
corrections are hard
folks sometimes uses hyperarticulation (“exaggerated prosody”) for correction, which trip up ASR
correction acts may need to be detected explicitly as a speech act:

dialogue policy
we can choose over the last frame, agent and user utterances:
\begin{equation} A = \arg\max_{a} P(A|F_{i-1}, A_{i-1}, U_{i-1}) \end{equation}
we can probably use a neural architecture to do this.
whether to confirm via ASR confirm:
- \(<\alpha\): reject
- \(\geq \alpha\): confirm explicitly
- \(\geq \beta\): confirm implicitly
- \(\geq \gamma\): no need to confirm
NLG
once the speech act is determined, we need to actually go generate it: 1) choose some attributes 2) generate utterance
We typically want to delexicalize the keywords (Henry serves French food => [restraunt] serves [cruisine] food), then run through NLG, then rehydrate with frame.