DOI: 10.3389/fcomp.2021.624683
One-Liner
late fusion of multimodal signal on the CTP task using transformers, mobilnet, yamnet, and mockingjay
Novelty
- Similar to Martinc 2021 and Shah 2021 but actually used the the current Neural-Network state of the art
- Used late fusion again after the base model training
- Proposed that inconsistency in the diagnoses of MMSE scores could be a great contributing factor to multi-task learning performance hindrance
Notable Methods
- Proposed base model for transfer learning from text based on MobileNet (image), YAMNet (audio), Mockingjay (speech) and BERT (text)
- Data all sourced from recording/transcribing/recognizing CTP task
Key Figs
Figure 3 and 4
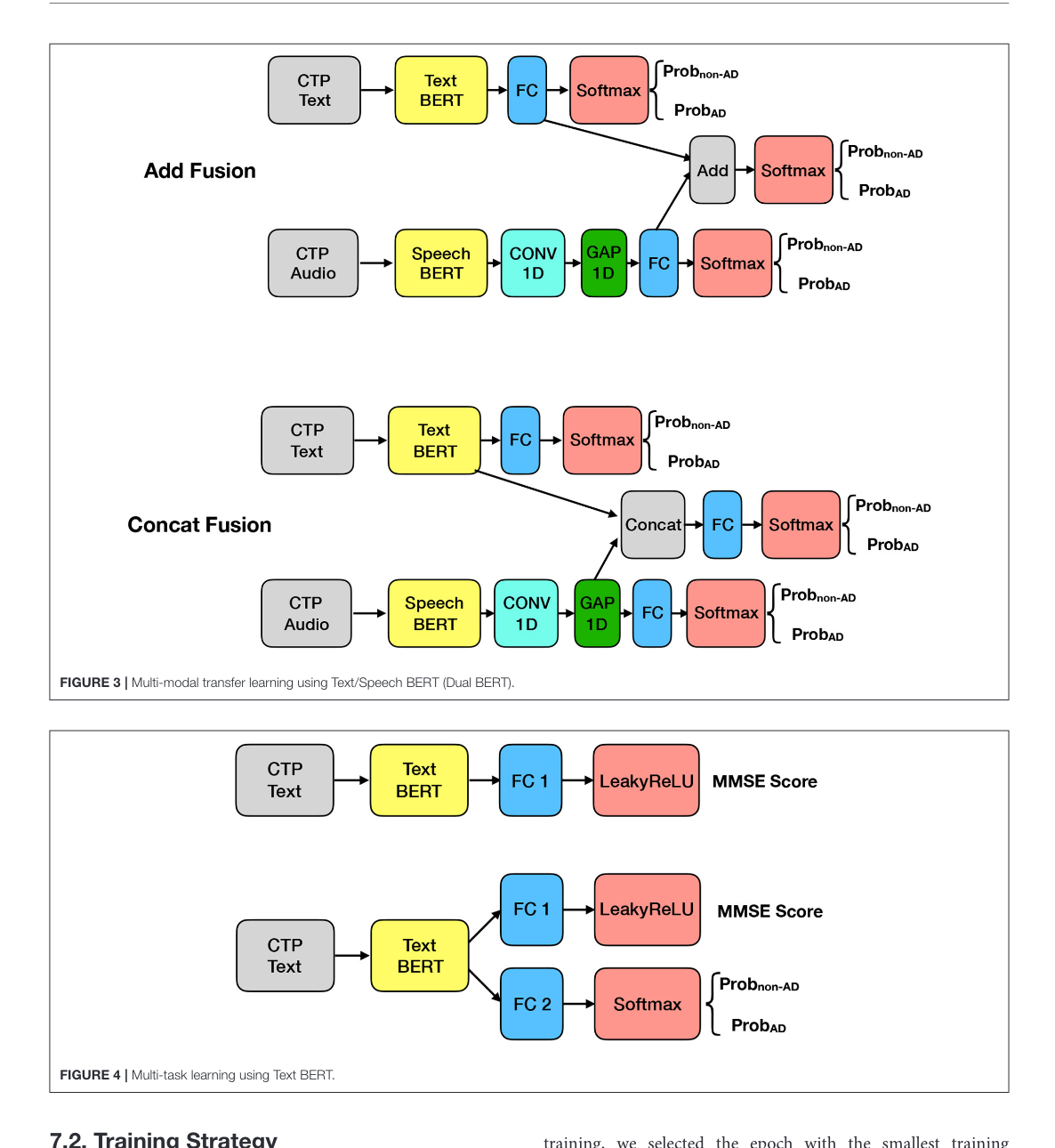
This figure tells us the late fusion architecture used
Table 2
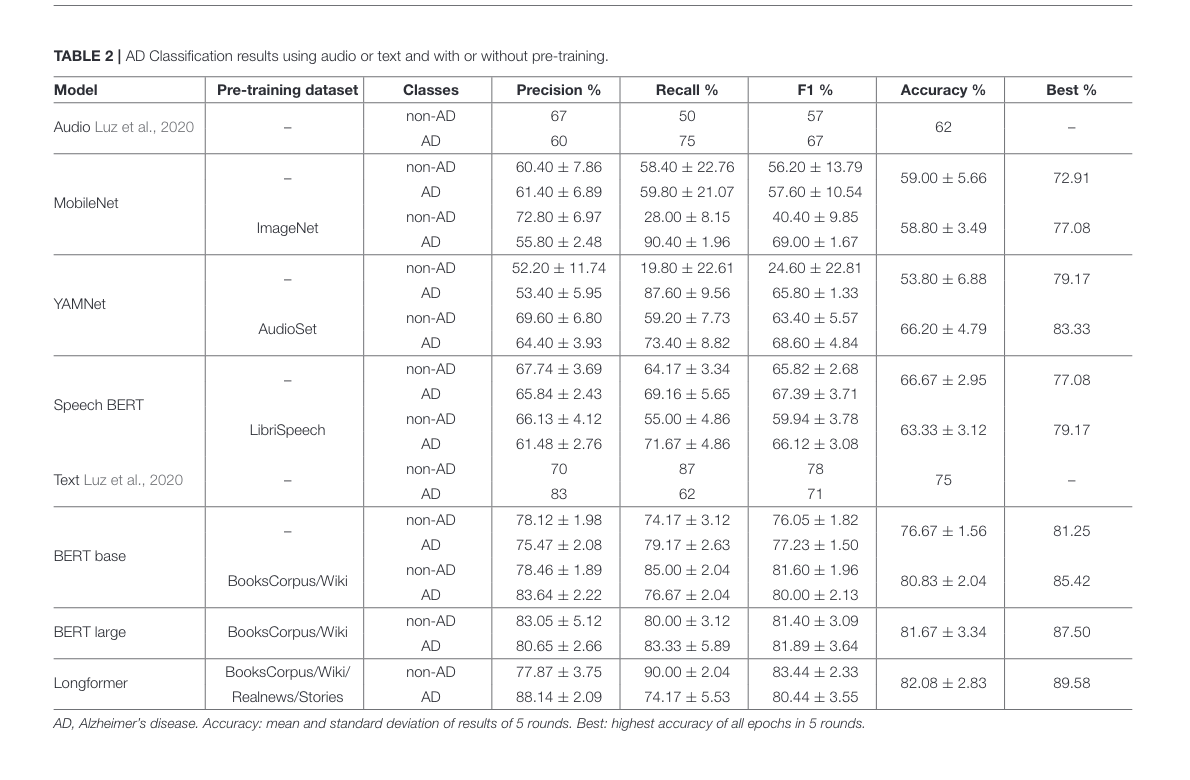
Pre-training with an existing dataset had (not statistically quantified) improvement against a randomly seeded model.
Table 3
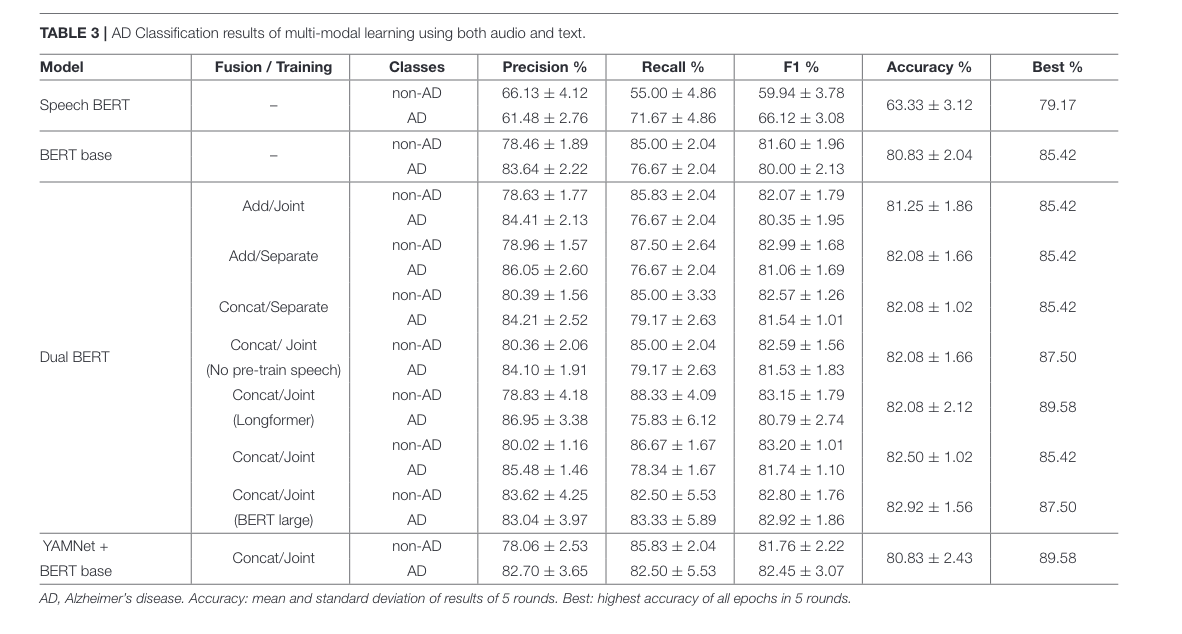
Concat/Add fusion methods between audio and text provided even better results; confirms Martinc 2021 on newer data