#Ntj
Sadeghian 2021
Last edited: September 9, 2022DOI: 10.3389/fcomp.2021.624594
(Sadeghian, Schaffer, and Zahorian 2021)
One-Liner
Using a genetic algorithm, picked features to optimize fore; achieved \(94\%\) with just MMSE data alone (ok like duh me too). Developed ASR tool to aid.
Novelty
- Developed an ASR methodology for speech, complete with punctuations
- Used a genetic algorithm to do feature selection; NNs performed worse because “space is smaller???”
Notable Methods
Used a GRU to insert punctuations
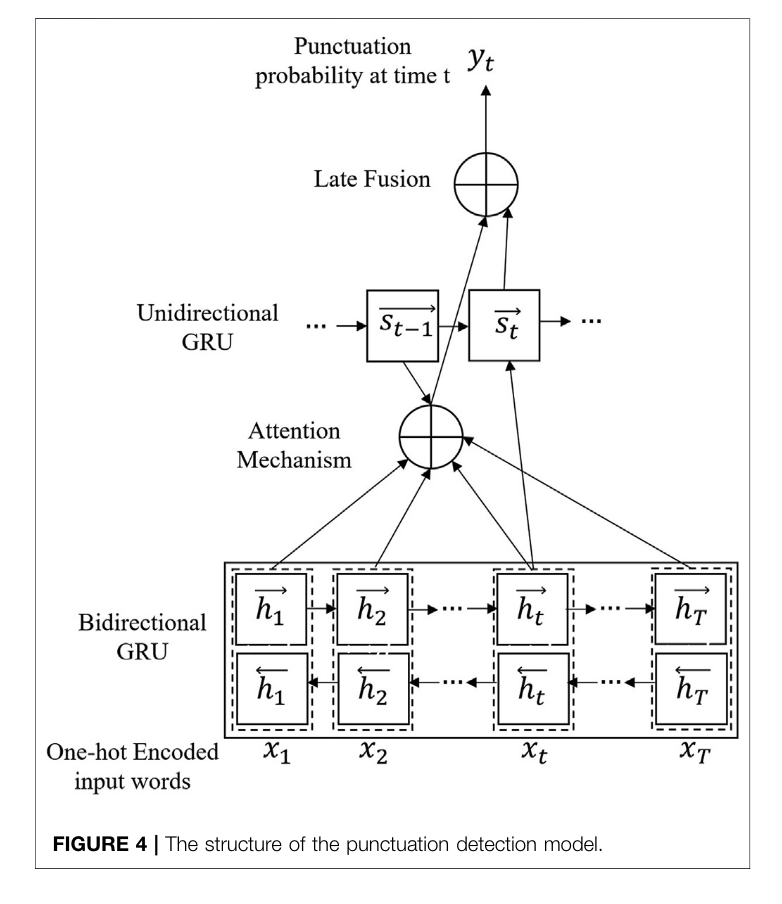
The paper leveraged the nuke that is a bidirectional GRU, ATTENTION,
Luz 2021
Last edited: June 6, 2022DOI: 10.1101/2021.03.24.21254263
One-Liner
Review paper presenting the \(ADReSS_o\) challenge and current baselines for three tasks
Notes
Three tasks + state of the art:
- Classification of AD: accuracy \(78.87\%\)
- Prediction of MMSE score: RMSE \(5.28\)
- Prediction of cognitive decline: accuracy \(68.75\%\)
Task 1
AD classification baseline established by decision tree with late fusion
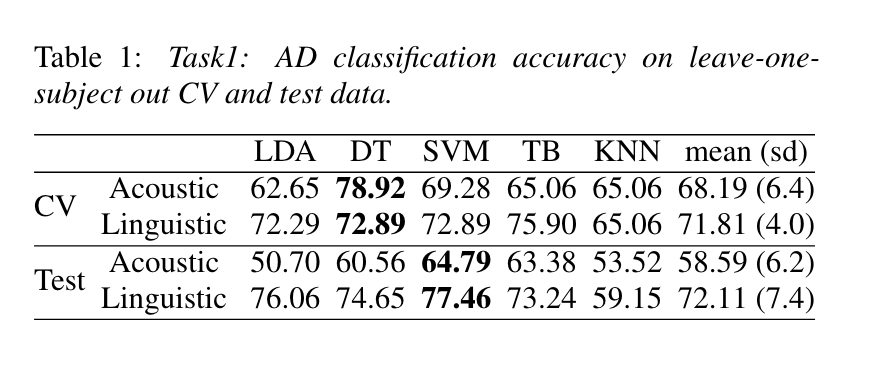
(LOOCV and test)
Task 2
MMSE score prediction baseline established by grid search on parameters.
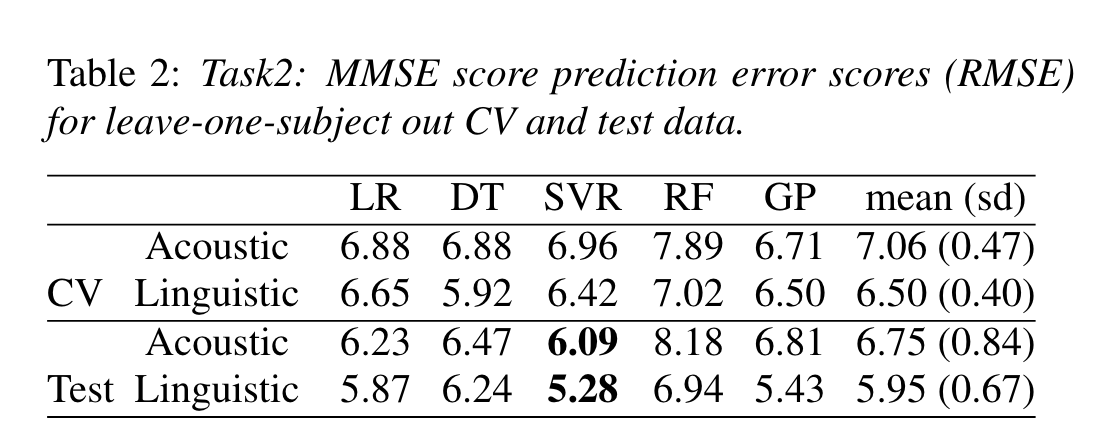
SVR did best on both counts; results from either model are averaged for prediction.
Mahajan 2021
Last edited: June 6, 2022DOI: 10.3389/fnagi.2021.623607
One-Liner
Trained a bimodal model on speech/text with GRU on speech and CNN-LSTM on text.
Novelty
- A post-2019 NLP paper that doesn’t use transformers! (so
faster(they used CNN-LSTM) lighter easier) - “Our work sheds light on why the accuracy of these models drops to 72.92% on the ADReSS dataset, whereas, they gave state of the art results on the DementiaBank dataset.”
Notable Methods
Bi-Modal audio and transcript processing vis a vi Shah 2021, but with a CNN-LSTM and GRU on the other side.
Balagopalan 2021
Last edited: June 6, 2022DOI: 10.3389/fnagi.2021.635945
One-Liner
extracted lexicographic and syntactical features from ADReSS Challenge data and trained it on various models, with BERT performing the best.
Novelty
???????
Seems like results here are a strict subset of Zhu 2021. Same sets of dataprep of Antonsson 2021 but trained on a BERT now. Seem to do worse than Antonsson 2021 too.
Notable Methods
Essentially Antonsson 2021
- Also performed MMSE score regression.
Key Figs
Table 7 training result
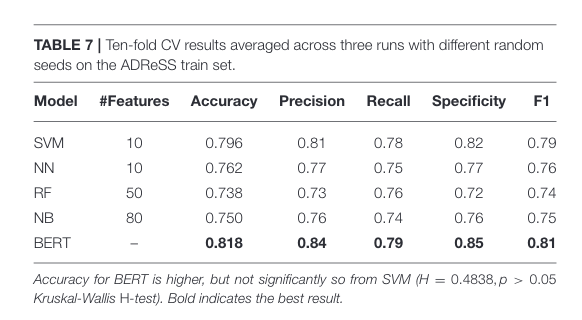
This figure shows us that the results attained by training on extracted feature is past the state-of-the-art at the time.
Guo 2021
Last edited: June 6, 2022DOI: 10.3389/fcomp.2021.642517
One-Liner
Used WLS data to augment CTP from ADReSS Challenge and trained it on a BERT with good results.
Novelty
- Used WLS data with CTP task to augment ADReSS DementiaBank data
Notable Methods
WLS data is not labeled, so authors used Semantic Verbal Fluency tests that come with WLS to make a presumed conservative diagnoses. Therefore, control data is more interesting:
Key Figs
Table 2
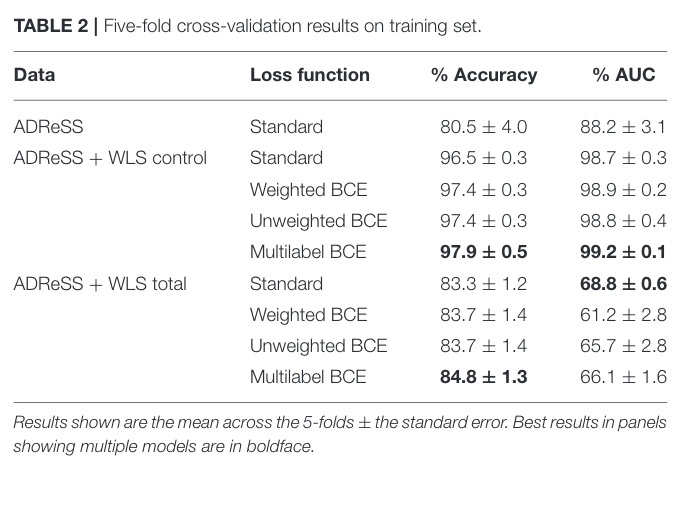
Data-aug of ADReSS Challenge data with WSL controls (no presumed AD) trained with a BERT. As expected the conservative control data results in better ferf